Fintech QA: Balancing Manual Testing and Automation
Although considered as one of the best practices for software testing, combining manual testing with automation can be challenging in reality. Understanding the importance of such duality is a great feat; however, most guides raise more questions than answers. There is also the problem of finding data on the relevant field of application.
In this article, we will talk about solutions applicable to the financial sector. More specifically, we will cover how this practice can benefit trading applications with various functionalities.

Understanding the application
Let’s assume that the benefits of each type of testing are transparent. While manual testing is more flexible for specific cases that require surgical precision and higher coverage, test automation provides consistency across an array of preliminary data, as well as clear test results suited for analytical statistics.
We then have to ask the question: which type of testing is our application better suited for? Would we apply the same rules to a metric-based system with external server-dependant integrations that relies on data manipulations as we would to a system that provides visual data that cannot be affected from the user side? Generally, the answer is “no”. The ratio between manual testing and automation should work towards the objectives of the application.
Let’s work through a couple examples.
Case 1: Consider a system that provides users with visual data on the amount of active orders in the book and their quantity. These orders are represented as bubbles on a map with price and time axes. The size of a bubble relies on the amount of legs as well as the sum of quantities of each leg. There is also a dependency on the side of legs and participation of other users in the book on the same price level.
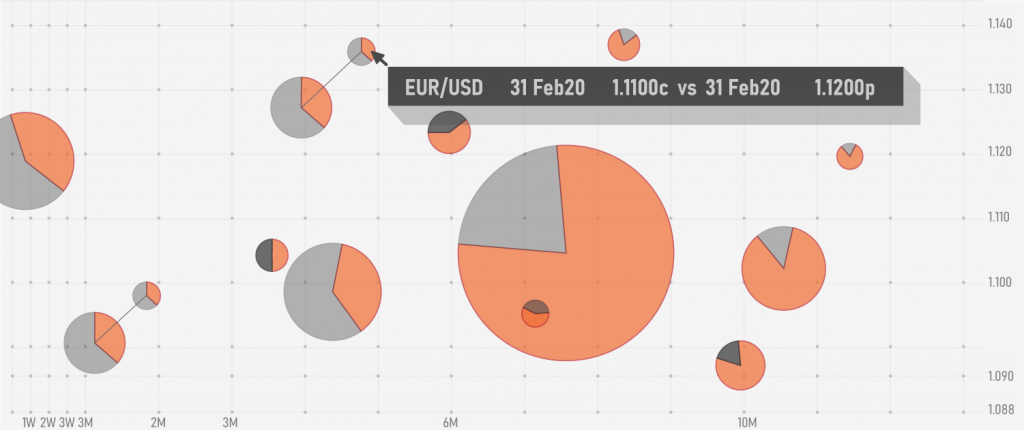
Would it be reasonable to automate size calculation of bubbles? Depending on the amount of combinations of legs, the number of possibilities could be endless but the calculation itself would remain the same. Here, we work with specifics of size calculation which could be checked by regular equivalence partitioning to monitor the dependencies of main variables. Seeing as this looks like the main use of the application, it would be cheaper to test the correctness of calculation logic by hand and leave automation effort for other purposes.
For example, we could dedicate automation to smoke testing of new releases. Set the parameters to check that the partitions are intact after every delivery: do orders of each side still use correct colour coding? Are orders of minimal and maximal bubble sizes optimally visible on the map? Can we still see the full set and relevant dependencies of 50 orders with varying amounts of legs? Does it slow down the application?
Case 2: Let’s consider a system that parses trading data to a back office application. The results are critical for checks by regulators and consist of a number of parameters each of which depends on a different calculation.
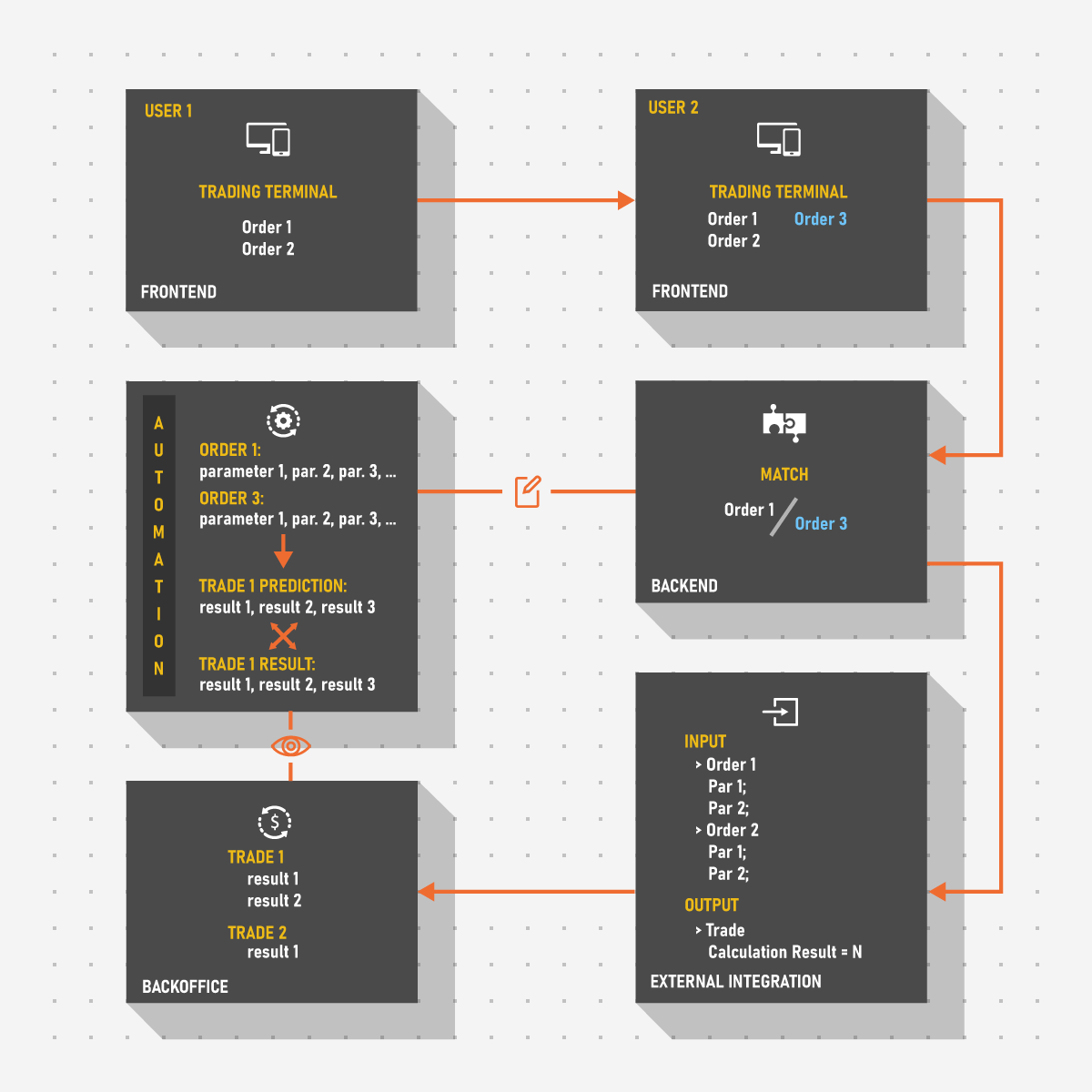
It is hard to imagine a situation where issuing hundreds of orders by hand is reasonable. Add the necessity to check negative scenarios and actual trading and we have hundreds on top of hundreds of cases which themselves hardly change from time to time. Considering this, it would be much easier to focus on automating the trading process to check if the resulting data equals a set of predictions rather than to go through each case by hand.
Yet, there might still be a need for manual testing. What if a new parameter is introduced? It would probably be wise to test it individually for codependencies with other fields first before including it into the automation grid. There is also always a possibility of emergence of unique cases that deviate from the sets of preliminary data. For example, a defect found by accident is caused by a variable provided externally. Having no way to set parsing of this parameter to manual, the logical step is to do the problematic calculation by hand: this way the set of parameters in control could be adjusted to the varying one, to simulate the scenario which has led to the discovery of a defect in the first place.
It’s important to understand that a problem rarely requires an unambiguous solution. There are many ways to address each challenge, including the examples above. The correct answer is the one that works for you individually. The idea here is that the combination of test types should achieve set objectives at the lowest possible cost. This usually implies determining the correct proportion: not every problem requires extensive automation and not every problem is effectively addressed with manual testing.
Bottom line: Determine the predominant testing type for your application. Use manual testing and automation in relevant proportions to fit the needs of the project.
Understanding the benefits
When the proportion of test types in relation to their usefulness to the application is established, another important aspect comes into play: utilize the strengths of each type of testing. The impression that automation can lead to more effortless testing is true to some extent. Nonetheless, it is important to remember the maintainability of the testing matrix and its initial deployment.
For now, let’s focus on the benefits of each type of testing individually and expand the concept expressed in the first part of the article. Remember that the objective is to carefully supplement, not replace each type of testing with the other, unless such action is dictated by the scope of the project. If the initial effort can be covered by a sole tester with extensive knowledge of backend and frontend intricacies, then perhaps deployment of a separate team for automation is excessive. In such scenarios, finding a person that could automate specific scenarios individually and apply a manual approach carefully to the rest of the system is more desirable in relation to the cost of the project.
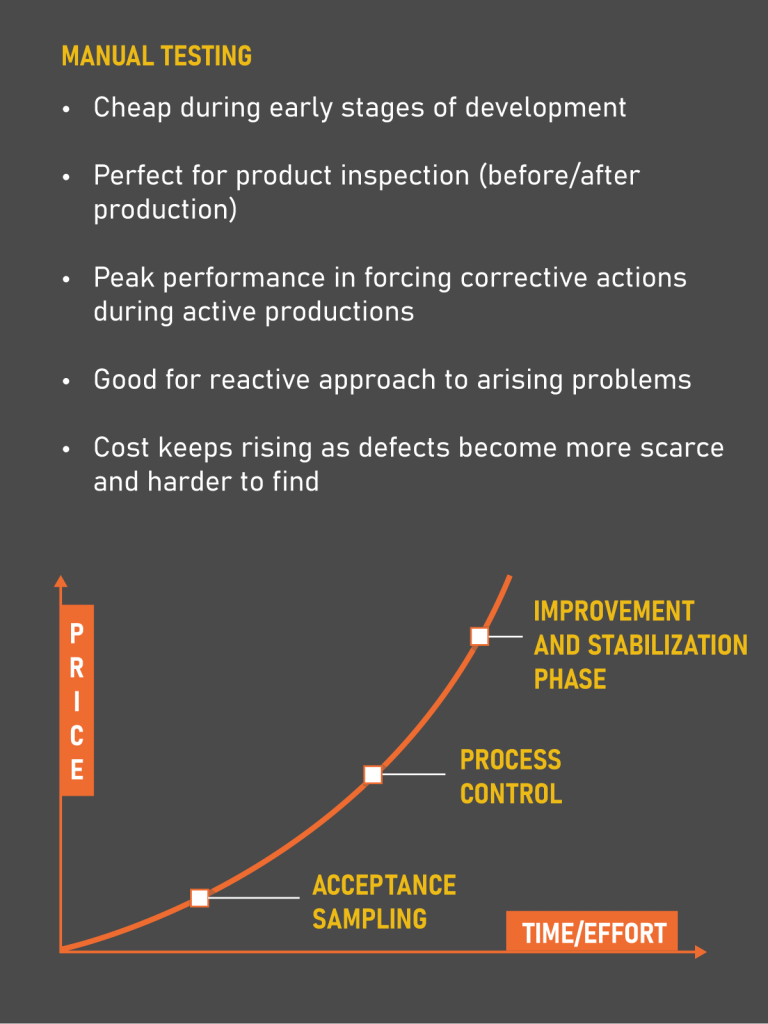
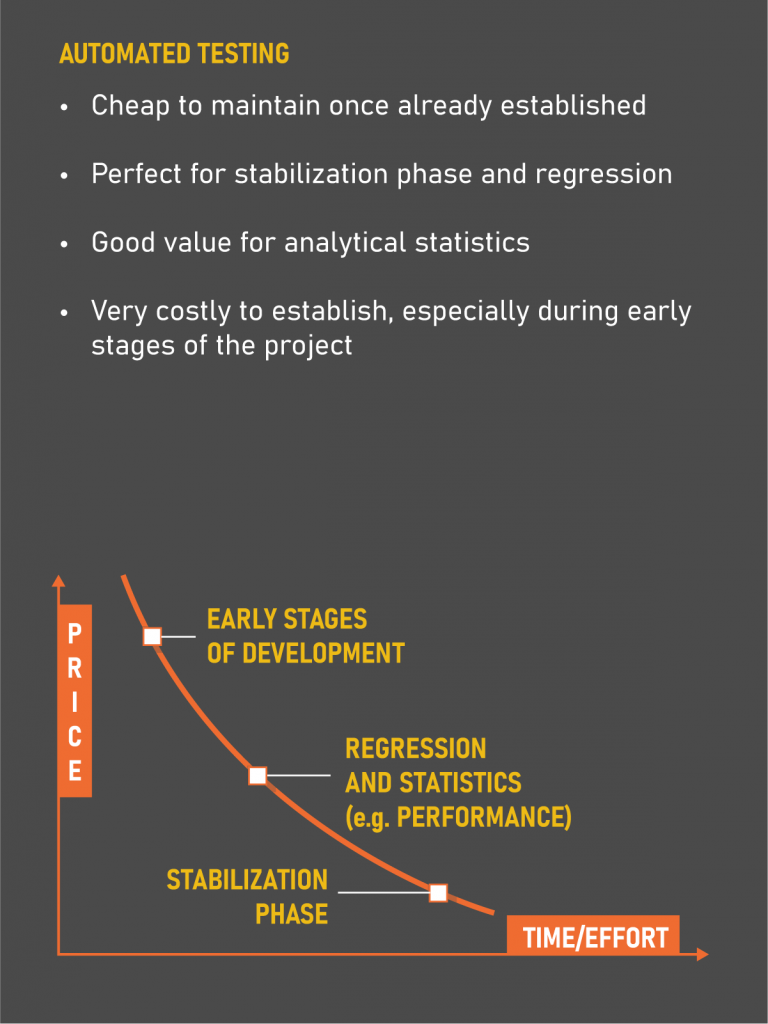
The main idea behind inclusion of automation implies fortification of the results provided by manual testing. As the project grows and new features are introduced, it becomes harder and harder to regress, which offers a great entry point for automation. For example, think of a validation system for orders’ prices entered manually by users. If the price deviates too much from a reference point presented as an external integration, it is not difficult to come up with testing partitions to test prices within the range of a validation corridor, out of the range and on the edge to test the core logic. However, considering the amount of combinations trading strategies present, it is important to test if this logic applies correctly to, for example, straddle orders, where the difference between sides can affect the cumulative price of the whole order. Would the logic hold?
One could argue that it is still doable by hand, and to some extent that it is true. However, as was mentioned earlier, what if some changes are presented to calculation logic or some other feature-specific area? A hundred test cases may not seem like a scary beast during the first regression run, but what about the second run? How would testers react after a dozen such runs? Not only does it become inefficient, but such an approach also willingly introduces the risk of human fallibility.
Introduction and gradual implementation of test automation could allow manual testers to focus on newly developed functionality to be more efficient with their release note testing. This way they don’t have to worry if a newly added feature would spoil previously installed operations. Now they have statistics to pinpoint problematic places or deviations for further investigative effort.
Bottom line: Understand strong sides of each type of testing. Manual testing helps on the edge of development while automation supports established functionality. Seek to supplement one with the other as phases of the project shift.
Understanding the downsides
Finally, it is important to keep operations in check as automation increases throughout the project. Testers should be reminded that finding the problem is not about creating a perfect script, it is about creating a script that perfectly finds the problem. Automation should not be primarily considered a coding challenge. If a test fails, it is not necessarily a problem of the test. An investigation into the problem that causes the test to fail should be introduced. If and only if such cause is not found, the test can be redone to skip the false positive result.
Obviously, it is not the only challenge. Automation on its own does not guarantee foolproof results. If at some point tests stop to fail, it is a good point to question if the data inserted should be actualized. Maybe even randomized if it was mocked in the first place? As such challenges arise, the cost of automation skyrockets. Reality checks should be made against the scale of the operation to reestablish if such effort is really necessary for the scope of the application. The established ratio between test types is a variable, not a constant, and can change over time.
For example, some table-based widget becomes deprecated and the data presented could not be actual anymore. At this point, testing code refactoring is due, so that false tests wouldn’t spoil the grand picture. Also, consensus should be achieved on whether the new widget or its reformed self should be automated all over again. Is it worth the investment? Does the core logic testing actually cover the new functionality?
Likewise, it is important to keep track of manual testing. If earlier features have not been stabilized during the initial phases of development and got stockpiled under a bunch of new ones, then maybe release notes testing should be postponed. At this point, it will be worth rechecking the earlier requirements to ensure the foundation of the application is firm and trustworthy to be built upon.
Bottom line: Keep the balance between test types to support the objectives of the application. Do not overdo one or the other to even the score as this approach can be costly.
To summarise
Unfortunately, fallacies of rare endeavors can be foretold seamlessly in advance. No matter how prepared the team may be, there will always be unexpected challenges that are not covered by guides or information articles.
We can adapt strategies and principles, general thinking, and study cases to expand upon and evolve further. However combining manual testing with automation still remains a learning process that is mostly unique for every business. The key to understanding the balance between the two approaches is to track tendencies and concepts that stand out and use them as anchors in the development of these practises.
The main idea still is to understand that automation is not the opposite of manual testing but a supplement. One cannot simply substitute one for the other, without understanding the context in which they are used. Almost any application can benefit from the duality of both test approaches but the ratio in which such codependency should be established is dependent on its specifics.
Bottom line: In essence, automation is the next logical step of manual testing, which aims to improve the basis of the project rather than to support its cutting edge. Dividing this unity limits the possibilities and limiting the possibilities adds additional risks.