Fintech QA: Continuous Integration in Testing

Continuous integration (CI) is usually associated more with development than testing. What is most commonly understood by CI is a process that allows developers to mitigate risks of integration conflicts as they work on the codebase. To do that the results of their work are merged into master-branch as often as feasible for any particular project.
Testing has become an integral part of the development process, and most companies rely on testers at least to some degree. It is no surprise that testing activities are included into the CI workflow and reinforce quality control among different application fields.
In this article, we will take a closer look at how the principles of continuous integration can be applied to a testing workflow in general and in the scope of development activities. To illustrate the concepts expressed in the article, we will be using fintech software, specifically FX trading platforms.
Shift Left the Continuous Integration Principles
Most would agree that it is easier to prevent problems than to solve them. As the testing process focuses specifically on preventing problems, both static and dynamic, it is a good idea to keep in mind the positives of continuous integration approach.
Consider the following scenario. A client wants to have a widget in their application that allows users to see their account metrics such as “Account Limit”, “Used Limit” and “% Used Limit”. These metrics respectively display how much a user can spend on this account in total, how much has already been spent in currency and in percentage of the total amount spent. Initial draft of the requirements is finalized, the design document is prepared, both of those are reviewed by the QA and reinforced with test cases. The result looks like this,

The feature looks ready for development and is left alone for some significant amount of time, let’s say two or three weeks of active development on other aspects of the application. Then, during one of the regular calls, the client suddenly comments that it would be better for values in account metrics to have separators for large money values instead of spaces. The analyst who is on the call makes a note and then corrects the requirements, but such a small change in Jira automatic mail is not noticed by the designer team who are busy working on another feature. A couple of days later the client sends an e-mail that states that they have reconsidered the wording as well, but unfortunately they forget to add the analyst to CC. The designers make the change in the specification and proceed to notify the testers that make the changes in the test cases.
All in all, the final variant desired by the client would then look like this:

But the implementation looks like this,

Colour coding was not implemented due to the lack of attention of the developers, separators were not added to the design document, wording was updated in the design but not in the written requirements, and finally some pieces of logic from another project slipped in (decimal precision for limit values).
Generally speaking, it is difficult to keep track of small changes in all project documents at once. They would not break the system if implemented incorrectly, but depending on the problem tolerance of any individual client, they could still result in a headache for the team involved. What usually happens in such instances could not even be called a miscommunication between teams, it is just human fallibility. However, applying the principles of continuous integration would help solving these problems.
Depending on where the requirements are stored, a team could find a single point of intersection between participants. For example, if written requirements are documented in Confluence and designs are stored in Figma, there still would be a Jira ticket (or a similar artifact from any other task tracking system) dedicated to that particular feature. A more involved workflow that revolves around specific tickets could then be established.
A team member that notices the change request assigns the intersecting item to the person at the beginning of the workflow chain who then passes the assignment to the following person in the chain until all parties have made necessary adjustments in their artifacts. Only then the item is passed to developers who break the change into separate tasks.
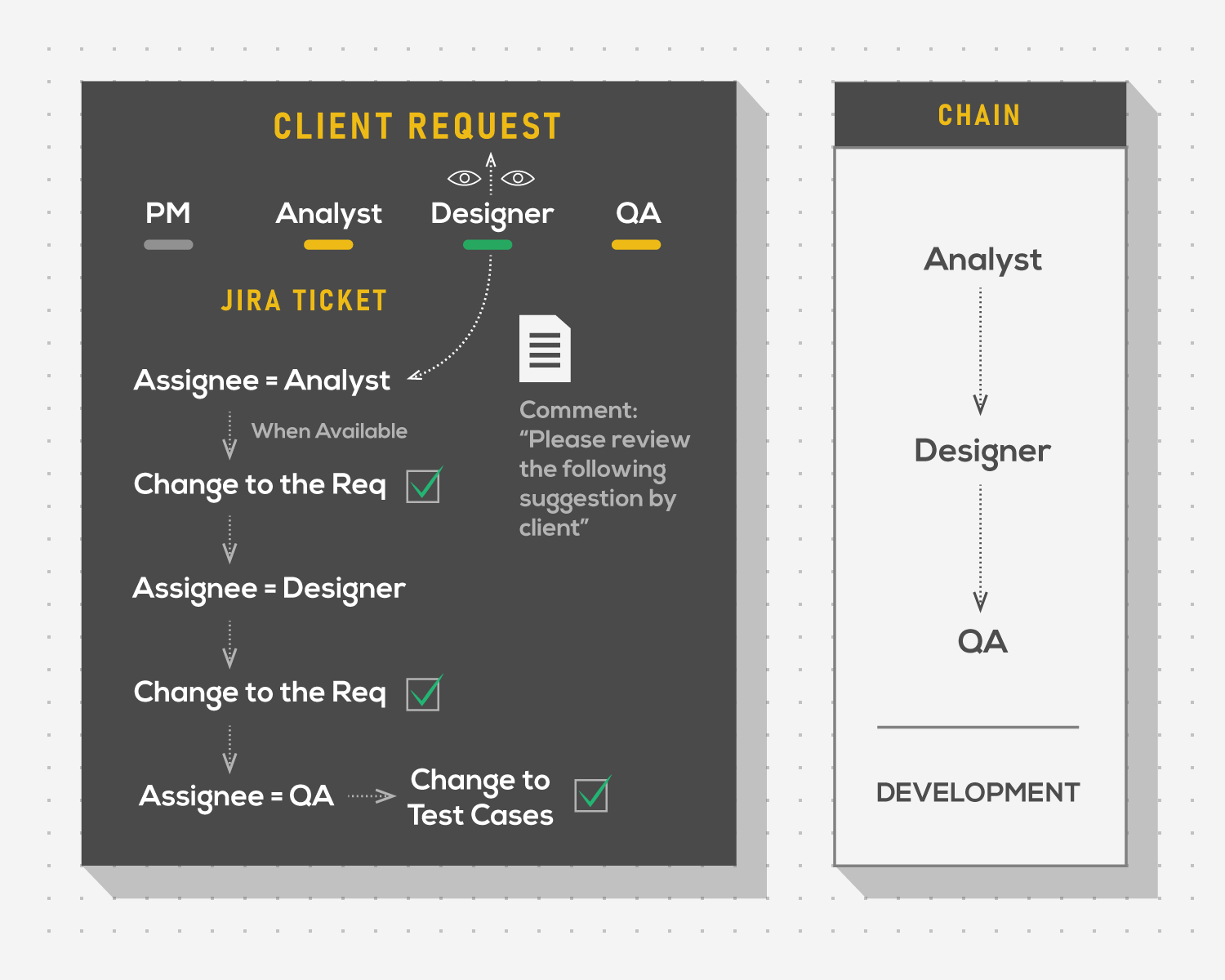
The form may differ, but the principle remains the same. Instead of processing client changes as separate small features, a set of big features should be defined beforehand and kept track of in one item per feature. For example, if there is a planned widget called “Trade Activity”, a single item for it should be created and updated with changes, instead of individual items like “Trade Activity Table”, “Trade Activity Pop Up”, and so on. This would allow teams to process features incrementally, by building on top of them in small chunks when necessary, instead of going for bigger updates and sacrificing smaller changes.
Of course, there are exceptions to every rule. Not every project is suitable for such version control and not every project even needs it. If fundamentals are strong but smaller pieces constantly change, nothing prevents the involved parties from creating individual features for every change by sacrificing additional time for their tracking and then sticking to the same checklists. The approach still allows teams to more effectively control the end quality of the product by continuously keeping documentation up-to-date.
Testing processes benefit tremendously from these effort investments. They allow testers to not only maintain their own artifacts better but to track the entire process in static — as opposed to looking for potential faulty consequences dynamically after integration into functioning components.
The largest downside, however, looks pretty obvious even from afar. The amount of effort required from all team members to participate in additional activity to track the documentation chain may not be viable due to budget, time, or other constraints. While the approach objectively increases the maintainability of the documentation, it requires strict protocol that is followed on every level. Unfortunately, this is not something every development process can afford.
Bottomline: The approach of continuous integration in static testing allows for better maintainability of the project documentation as more people are involved in keeping up with the whole documentation chain. The downside to this is that the approach requires extra time and effort investments from every involved party.
Dynamic Testing in Continuous Integration
While application of CI principles to static testing and documentation may seem like an overkill for some projects, the majority of development activities could benefit from including actual testing into their CI workflow.
The most straightforward approach to releasing newer versions of any software includes a host that is used as a testing platform for both developers and QA engineers. After some amount of PRs are merged into the master branch, a build that contains these features is prepared and delivered to a dedicated playground. This is where testers perform release notes testing on the system level, checking the changes in one integrated package. However, if something goes wrong in the codebase, it may be difficult to unwind the changes and fix the problem.
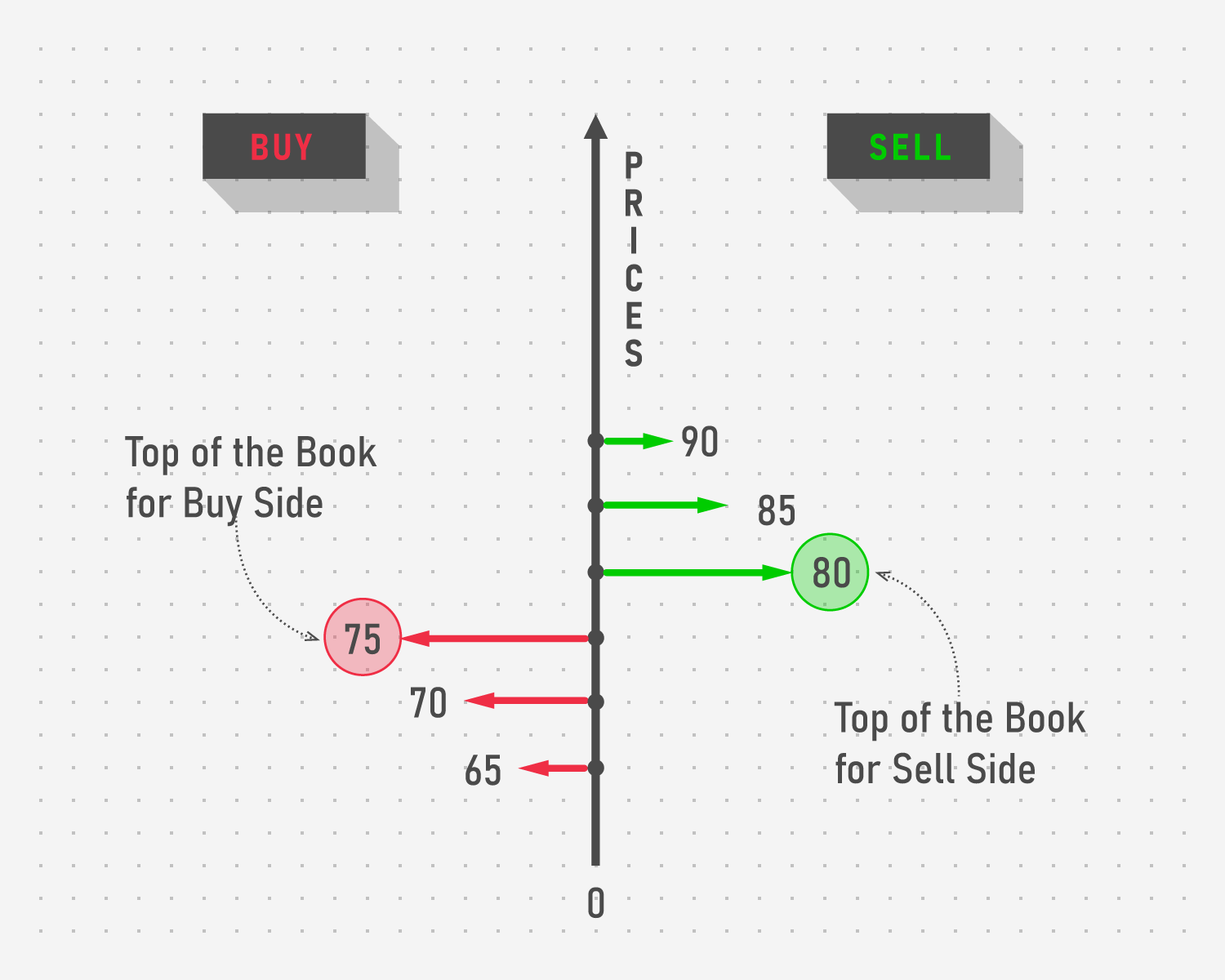
Consider the following scenario. A client wants to implement a widget that allows traders to observe the best available offers on the market for one particular strategy. The offers are placed into what is called an order book where the best ones form the so-called top of the book. For example, imagine an option contract opened on some Stock instrument that grants the buyer an ability but not an obligation to perform a deal at some time in the future. The parameters of such an option (like the price at which the trade is done or the time on which the trade may take place) form an option instrument for which different parties can bid and ask different prices. The higher the price of the Buying side, the more profitable it is for the Selling side to match with, and vice versa. The best price from each side forms the top of the book while still allowing other users to keep their orders in the order book at any price they want.
The feature is developed by a team that is involved with a number of other projects so that their knowledge about and involvement with the business domain is limited. To the best of their ability and understanding of the requirements, the developers implement the feature that works as intended. However, as more and more complex additions are introduced over the time (like cross-matching across several price levels, stocking remaining quantity into the book if traded at more than initial notional, and so on) the lack of business knowledge begins to show. Eventually, one Change Request breaks the widget, a fix solves the initial problem but introduces yet another one, causing the chain reaction of defects that now leave the widget in a sorry state.
Testers spend their time checking the release notes leaving a trail of defect reports that demoralize the whole team, wasting their time describing similar problems over and over again, until a decision is made to rework the widget from the ground-up.
While hyperbolized, the example still demonstrates the weak point of not including testers into the process of continuous integration of code. If the team had adopted a more flexible process allowing testers to build the environment locally, the merge of PRs would have been prevented at an earlier step. Testers could have explained the business domain to developers in detail at the PR review stage, leading to better code and as a result better software.
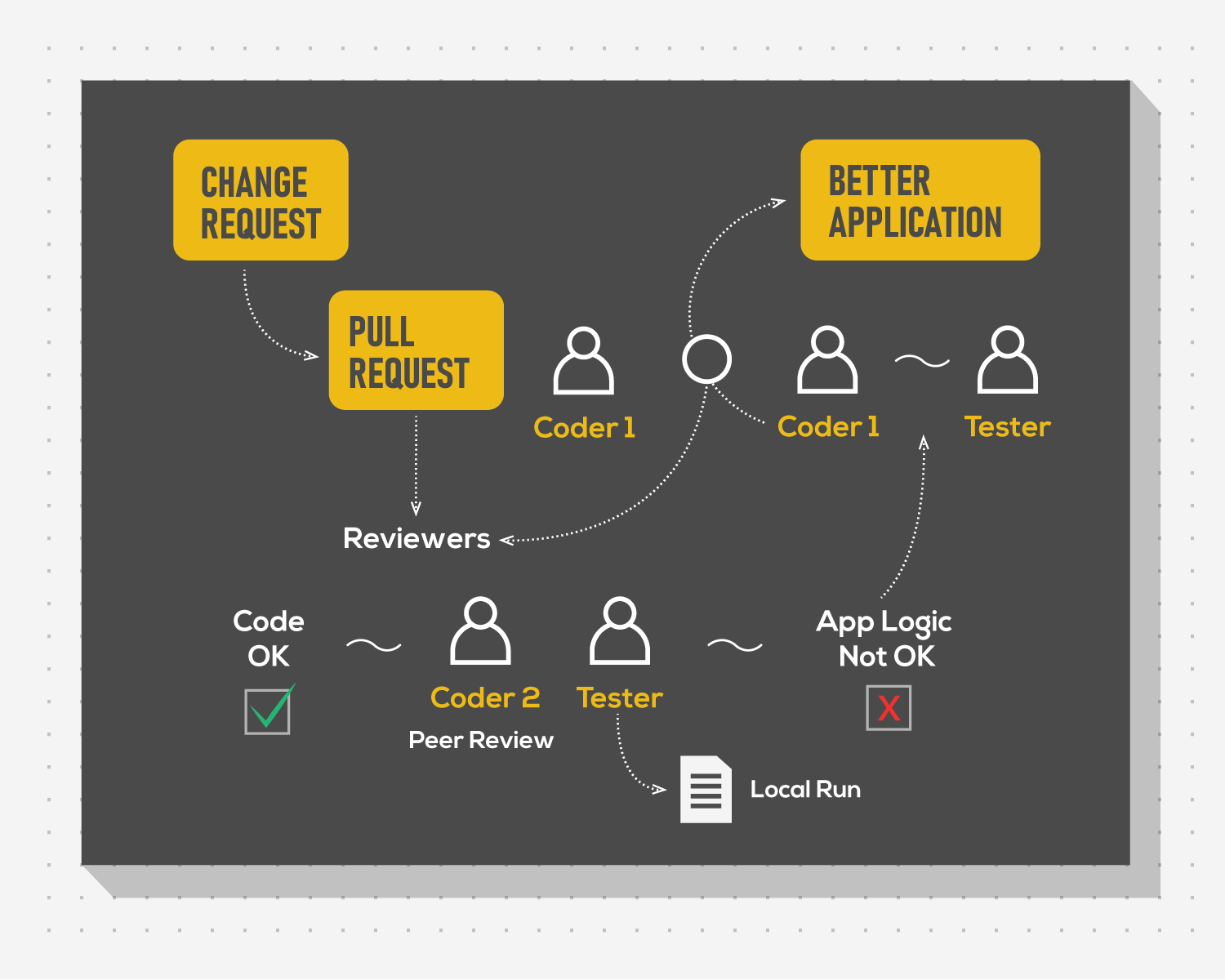
On paper this sounds like a bulletproof solution. If the result of introducing testers into the continuous integration flow is so advantageous, why do some avoid it? The problem lies in several aspects:
- The time investment required to set up such a process is usually measured in weeks and months. While it may be okay if thought of at early stages of the project or if the resource budget allows it, usually the reality is the opposite. The alternatives may work successfully too and cost significantly less. It is an unexpected turn of events that may require switching to a more adaptive workflow.
- This form of in-sprint testing rarely allows testers to look at the software on a system level before major releases. While individual pieces of code may work as expected, the continuous merge of changes may still result in integration conflicts that are likely to go unnoticed until the most unfavorable timing.
- To counteract the previous point and maintain stability without regular regressions, extensive automation is highly advised. This guarantees at least some level of certainty for those parts of the system that lay out of reach during local testing of individual PRs. Obviously, an automation grid cannot be established in a week or two, especially if the project features several independent modules, which is a whole other topic for risks and costs.
As one would expect, the answer lies in the middle. Inclusion of testing into continuous integration is project-specific and should not be used as a universal principle. Its benefits should be compared against the odds to make a decision on the necessity of such workflow.
Bottomline: Allowing testing into continuous integration processes lets testers provide feedback earlier and prevent the merger of feature-breaking PRs. At the same time, the establishment of such a process may result in unnoticed system-level problems while requiring the infrastructure to support it with potential necessity for testing automation.
To summarise
Continuous integration as a practice has been part of the development process for a long time. As testing becomes more and more important given the expansion of IT technologies, solutions are required to merge one process into the other.
This unification, however, may result not only in benefits but also in new challenges, both in static and dynamic testing. This includes the shift of focus from more pressing matters to the process optimisation for static testing or infrastructure amplification for dynamic testing.
While it is good to improve the process to make it more infallible, sometimes scaling up is not required. This should always be a point of debate during project definition and outline.