Pre-Release Regression Testing in Fintech
When testing software, we separate the process into stages. Probably the most important stages for business are pre-production and pre-release. Let us leave pre-production for another discussion and focus on the importance of pre-release testing or – as it is more commonly known – regression testing.

The regression testing can be performed in different phases of the project: milestones during development, before major demo releases, between major updates, or on the brink of a go-live. Each of these has certain differentiating aspects that define the scope and risks, but today we will be focusing on a go-live regression testing.
In this article, we will be discussing how to ascertain risks and prepare the regression run, how to execute it within a defined time frame, and how to work with the findings. As an example, we will be examining a solution for financial markets, more specifically an OTC Forex-trading platform. This article will be most helpful for people that understand underlying trading concepts but would be interested to know about the testing side of things as well.
Definition
Regression helps the development team limit the risks associated with the implemented changes. For example, if the recent changes to the dealing workflow are significant, they can affect the operation of the platform not only in the scope of a certain window, but in other functionalities as well.
Let’s say a commission calculator ignores the maker’s point of entry for the Offer side in Options trading. If the issue is introduced on the backend side, this could affect areas in the UI that employ calculation methods. Alternatively, if a single controller for UI specifically designed for the dealing workflow uses an incorrect method from the backend, this would not affect other areas of the application.
To make this a bit more apparent, let’s assume that commission is applied to the gross premium, which is calculated as a percentage of the used notional. If a trader wants to issue an Option from the selling side, they would be willing to perform some kind of operation (buying or selling the underlying) in exchange for a premium. For example, if the trader issues a selling EUR/USD Option on a 10 mm notional set at a 1% of price, they are willing to perform a trading operation in exchange for a 100 000 EUR premium that the taker of this Option will pay them. Additionally, said trader will have to pay commission to the holder of the platform for hosting their Option. As the side of the operation is “Sell”, it means the maker will receive a premium minus the commission, so the net premium becomes gross premium – commission.
If we expand this logic by saying the same calculator is used on the order issue screen and in the dealing screen at the same time, we have a varying risk based on where the issue is, backend or frontend.
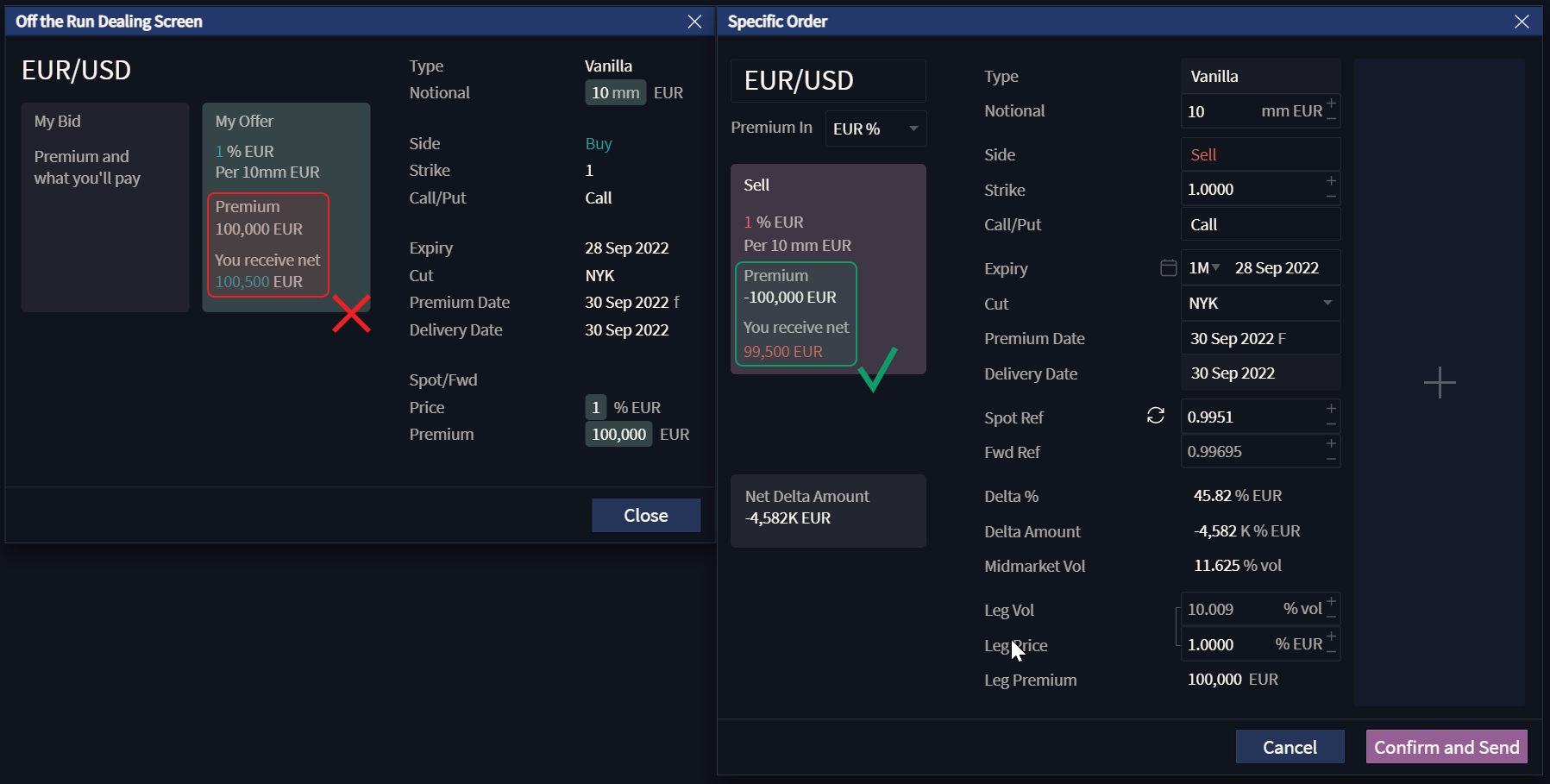
The above scenario defines the main problem of regression: risk estimation. This should not be an issue when the project needs the whole application tested from the ground up (as testers would have to test everything either way) – but even then some areas are more crucial to the work of the system than others and would require excessive attention.
The problem of risk estimation is further expanded by the principle that exhaustive testing is impractical and close to impossible – except for trivial cases. Instead of trying to produce bug-free software, we can focus on pinpointing the main risks and their mitigation during the definitive phase in which entry and exit criteria for the regression are defined.
For example, the main entry criteria can be defined as a set of items:
- having no Jira epics that describe functionality still in development
- having full formal requirement coverage (even if there are still questions present)
- having the requirements cross-referenced to test cases that check functionality that is dependent on common methods employed by other competencies
- e.g., the backend calculator above that is used by frontend in several places – this allows to limit the risk areas by putting higher priority on relevant test cases.
- having the test grid or testing matrix extended over all described functionality
- this statement and its actual usefulness will be investigated closer in the next section.
The main exit criteria in the supposed scenario could be:
- having no test cases that still require execution per functionality (or epic if we use Jira terms)
- no open items per functionality for development
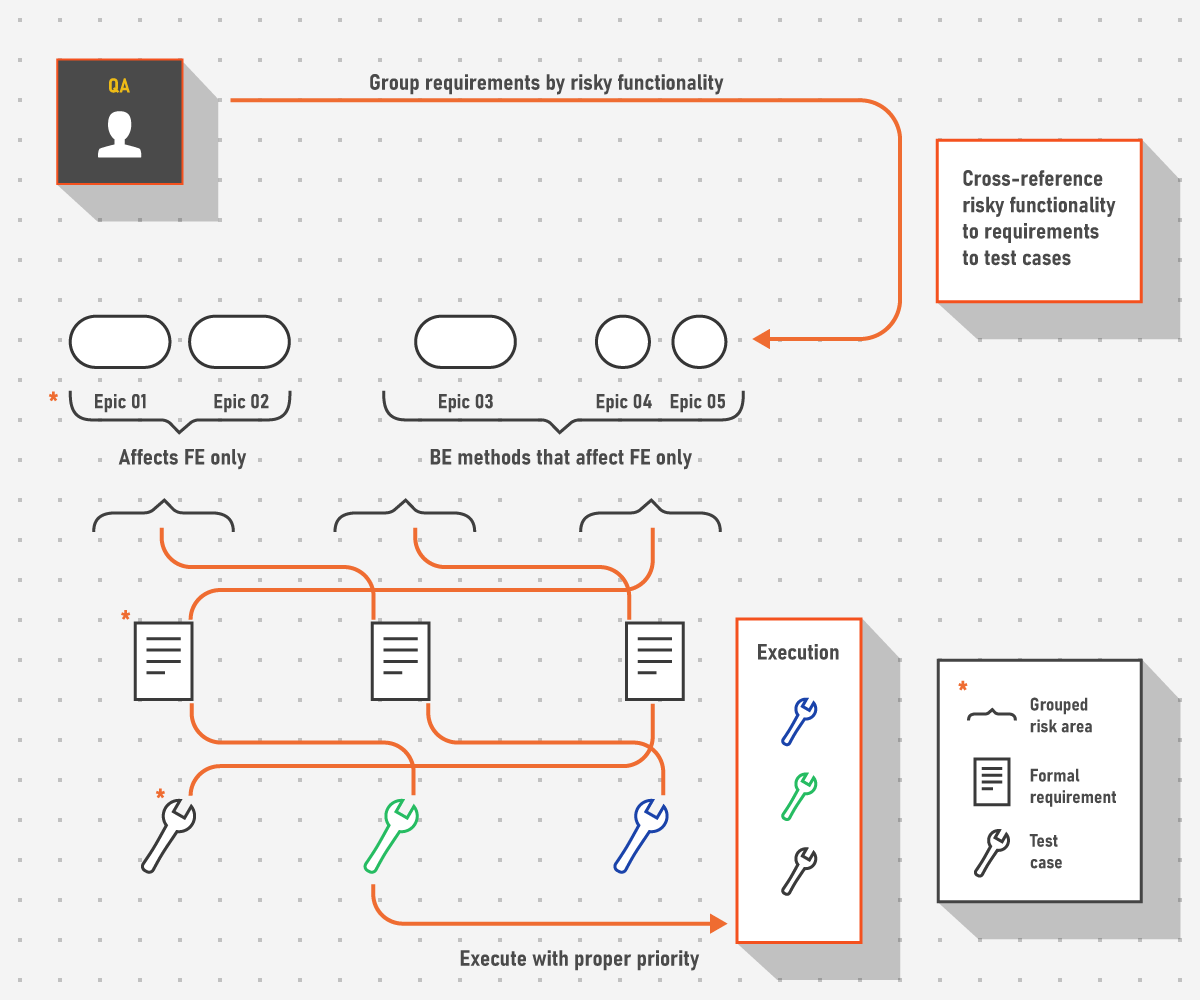
Bottomline: Exhaustive testing is impossible so focus on problematic or high-risk areas of the application when performing any kind of regression. Even thorough regression benefits from prioritization as critical issues are found sooner.
Execution
When entry and exit criteria for regression are defined, the regression run is executed. In this article, the process of executing test cases itself will not be covered, instead we will focus on the areas that can help us test either entry or exit criteria.
1. Entry Criteria
A test case is essentially an atomic scenario that executes part of the functionality to reveal adherence to certain expected results or deviation from them. The actual form of a test case is not important as long as it follows the main principle. The regression can be performed with just formal requirements or a list of user stories, the necessity of which depends on the complexity of the solution.
An experienced tester can execute the commission calculation logic without a written test case because the logic is based on general trading principles (not even Forex-related) and potentially without formal requirements because those only specify exact modifiers. The focus here is the reporting expectations of the client and the deadlines for preparing the testing matrix.
Obviously, the more described a test case is, the easier it is to execute for less-skilled team members. However, high-level test cases also have obvious benefits such as time saving and the fact that different testers will use different test data. High-level test cases also help form a test grid even if the only descriptive part is the summary with everything else depending on the engineer’s knowledge.
The testing matrix in and of itself is just a tool that helps maintain progress and define uncovered places of the application. Its necessity can vary based on the scale of the project. For example, if the application only allows monitoring of tickers for a limited, fixed set of FX instruments, the team won’t need an extensive testing matrix to report the progress or monitor all the features.
2. Exit Criteria
The end results of a regression run is a list of found items and statistics that show problematic areas. For a pre-release regression the main focus is to locate MVP-scope items and hotfix them before going live.
An extensive testing grid with formal test cases allows for a precise report with proper statistics on the overall amount of found issues. High-level test cases may miss some more evident but less important items in favor of inspecting high-risk areas and testing edge cases based on testers’ experience.
How extensive the report should be is negotiated with the client when resources are allocated at the start of the project. This allows for a proper testing matrix or, alternatively, a deeper focus on exploratory testing.
For pre-release regression runs, the main artefact is a list of problematic items prioritized based on the objectives of the project.
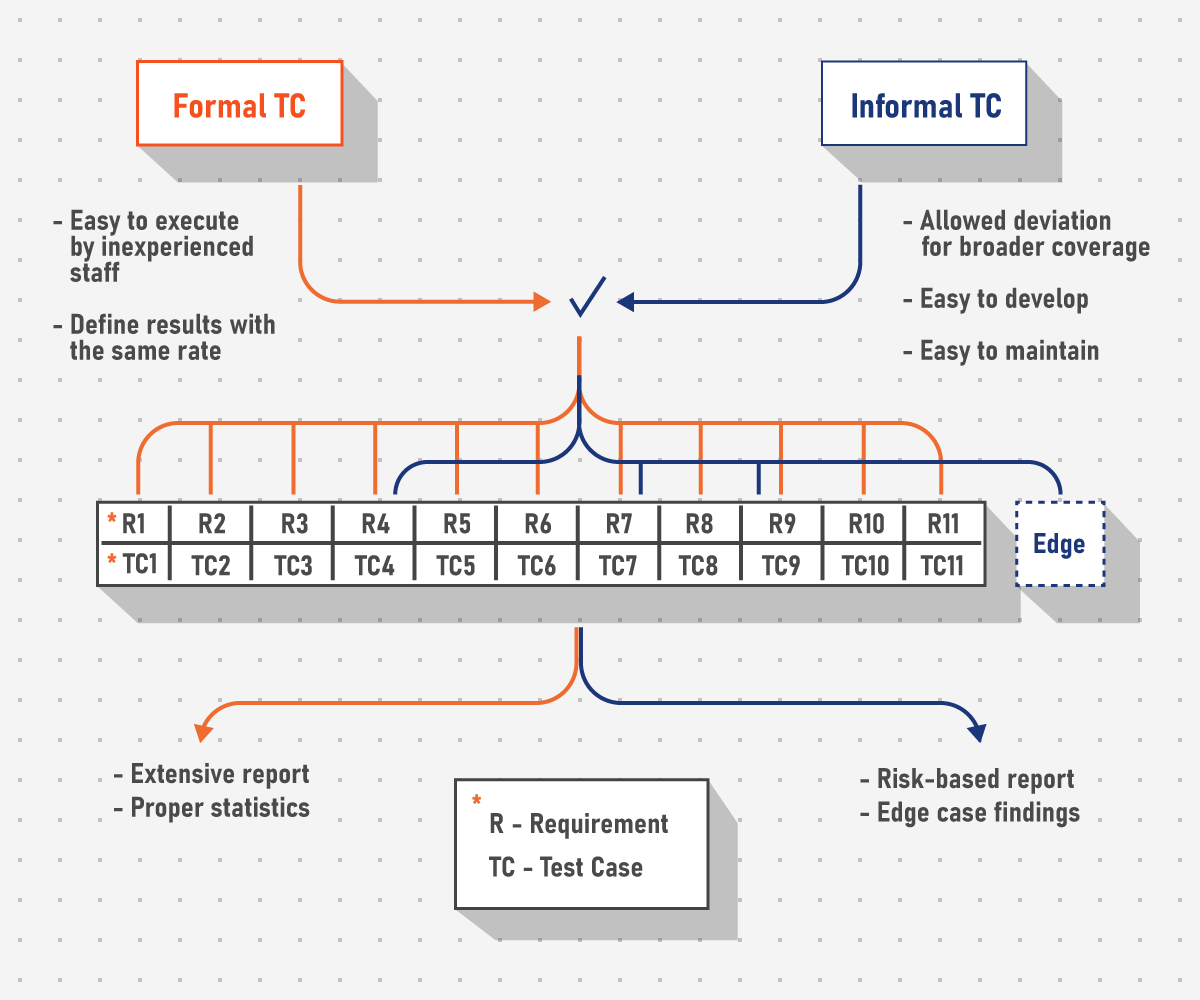
Bottomline: Regression execution focuses on confirming the stability of the implementation in relation to requirements while also providing statistics based on what the client expects. If the system is regularly regressed at milestones, edge cases can be more important than an extensive report and vice versa. Testers choose which types of test cases will be executed based on the goals of the phase.
Results Processing
For pre-release regression, when the run is complete, it is necessary to process found issues that prevent the project from going live. The definition of the MVP scope should be a combined effort of the development and client teams.
For example, a successive change of developers during earlier stages of the projects may result in significant overhaul and refactoring. The team can continue to plug the holes with minor fixes, but each change introduces new problems because the code is very difficult to maintain. In order to fix the issue, the development team may suggest fixing only the most critical issues immediately leaving some MVP items until the patch is released.
The most important aspect for pre-release regression is to move into a release branch and apply only minor code changes so as not to jeopardize the regression results. Otherwise, the incompatibility between components that stacks up after every cascade merge could affect not just the release branch, but the master branch as well.
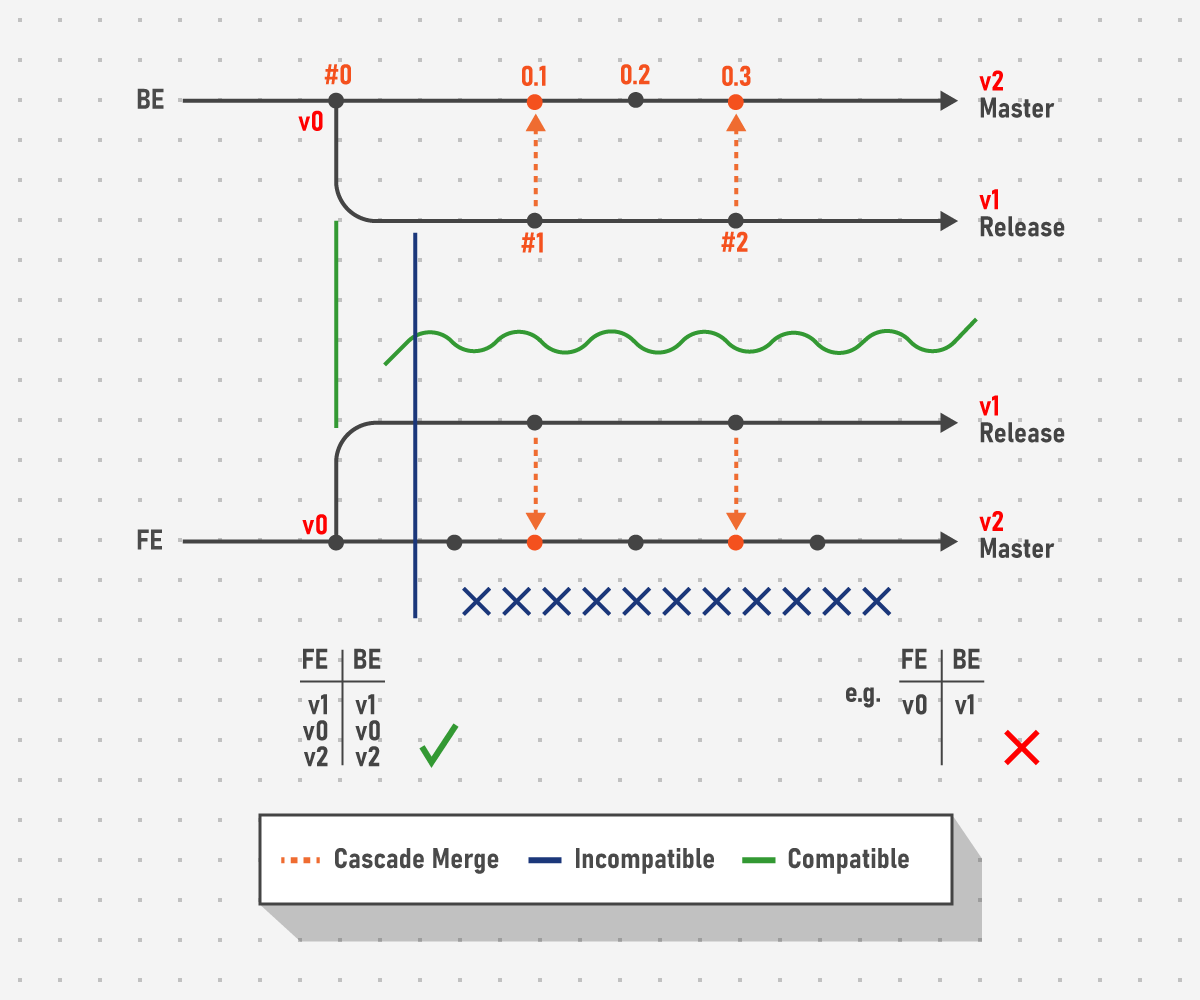
Alternative to that is countless iterative runs of the same regression that not only postpone the production date, but also occupy the involved QA engineers that would have been doing more meaningful work, for example, focusing their attention on upcoming phases and new functionality.
Bottomline: Hotfixes required after pre-release regression should be applied in a separate branch so as not to affect the master branch. More importantly, backwards integration of new tickets from the master branch (e.g., new functionality) into the release branch should be strictly prohibited so as not to break the stable build.
To summarize
Regression testing is a tool that allows both client and development to determine how stable the current release is and whether it requires any immediate adjustments to become a milestone.
While it is impossible to find every problem, the main focus of pre-release testing should be on finding MVP-crucial items that could affect the initial impressions of the end users in the production environment.
The fixes for these items should be applied in a controlled manner, and certain problems need to be taken as a risk rather than a necessity for immediate fix. The alternative could cause iterative changes and destabilize the build, locking the development team in an endless cycle of creating new problems by fixing the older ones.