Capital Markets Software: Risk-Based Testing Challenges

Watch Dmitry’s talk on risk-based testing challenges at the recent QA Financial Forum.
Introduction
There are four main challenges teams usually face while implementing automation testing — or any testing in general:
• Coverage — ability to track amount of requirements being verified
• Test data — ability to prepare valid data assets to test with
• Configuration — ability to identify and provide required testing setup and environment and make sure execution goes as designed
• Reporting — ability to articulate testing results for decision making
The industry is in really good shape when it comes to dealing with these challenges. There are plenty of great tools available to help us build our test management system, so a typical software pipeline is a superposition of these tools.

But as our products and processes mature, new challenges arise, such as:
- Coverage — is it possible to apply dynamic risk-based testing?
- Test data — how to operate shared test assets and system states?
- Configuration — how to manage an ever-growing number of unique execution pipelines and operate them effectively?
Let’s dive in and try to answer these questions.
Risk-based testing
Risk is the probability of an unforeseen event that can negatively affect the behavior of a software product and, therefore, the entire business. Risk identification, assessment, and mitigation are thus vital parts of any SDLC. These activities play key roles in product release planning, especially for businesses offering 24/7 service, like our clients, who are stock or forex brokers and cryptocurrency exchanges.
Risk-based testing is a technique that uses risk assessment to select and prioritize test suites and test the most critical and risk-prone blocks first.
Risk-based testing is essential for Agile teams working in intensive sprints, as it is the best way to get the highest possible quality within a given timeframe. And most importantly for automation teams: risk-based testing is applicable to expensive types of test automation.
To understand that, let’s look into the ‘expensive’ part, as some may say — ‘automation is free, it costs nothing to run once written’. Well, it costs something — let’s do the simple maths.
Combinatory overdose problem
In a relatively common trading system, there are two account types (Cash and Margin). One can use order types (Market, Limit, or Stop) with five time in force1 instructions to buy or sell assets (stocks, bonds, funds, metals, futures, options, Forex, CFDs or Crypto). Orders are placed so as to be triggered by price, and you can edit or cancel them, while, depending on the current market situation, the system can expire, reject or fill them, or fill them partially.
Therefore, exhaustive testing of such a simple system would require
2 × 3 × 5 × 2 × 9 × 8 = 4320 combinations
Let’s assume we have perfectly stable, predictable and bug-free UI automation giving us 30 seconds per combination. In this case, running these tests in 10 threads will take 3.6 hours for full execution. And that’s not even counting in other use-cases, like registration, position management, account statement and reporting activities, etc. Obviously, 3.6 hours is not acceptable for any CI/CD process, and produces more CO2 than sense.
Solution
To balance benefits and expenses, execute only a selected subset of automated tests. Query cases through the test management system and programmatically fetch them from the codebase to create a custom execution batch.
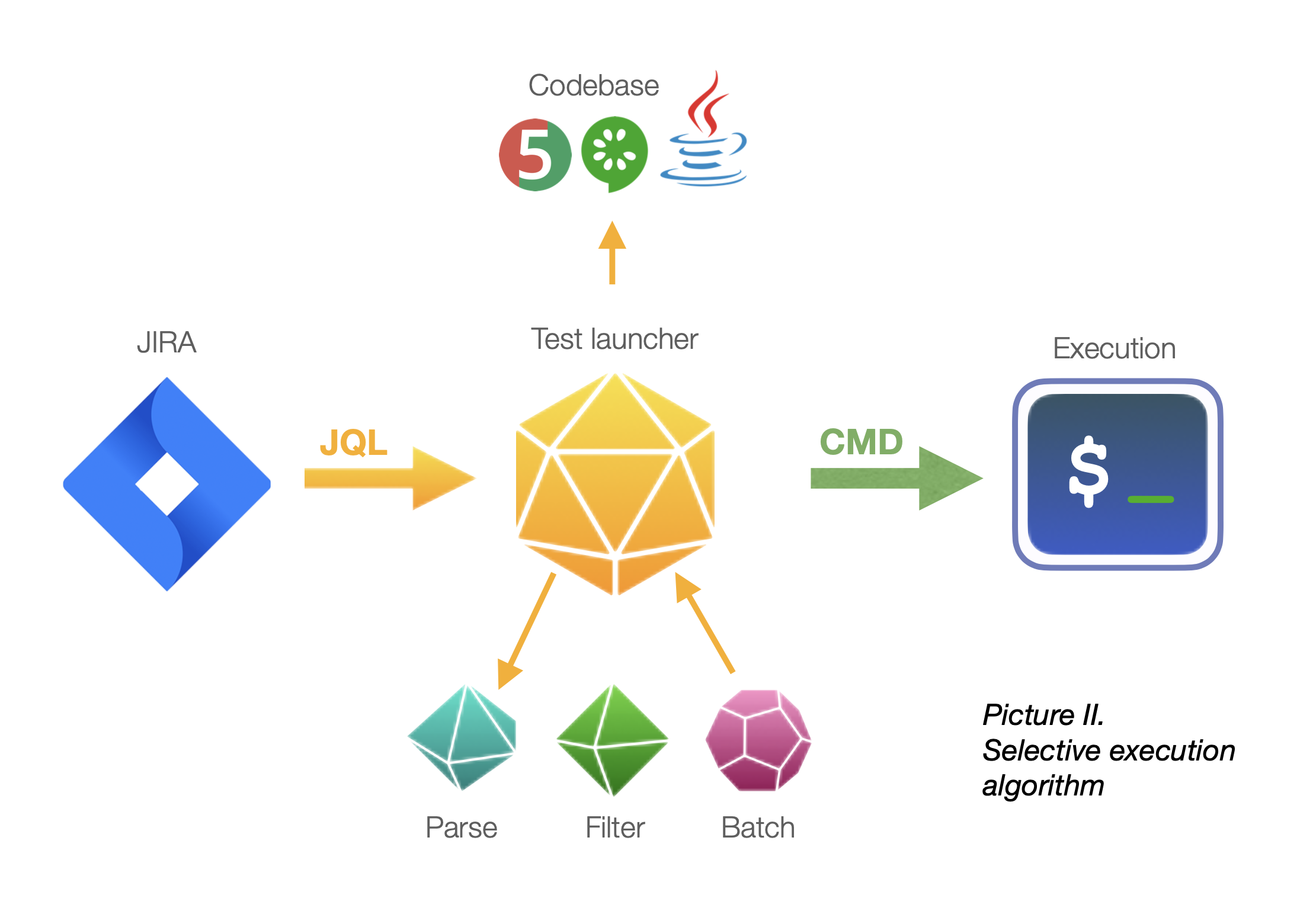
For each sprint, based on the product backlog, you can semi-automatically tune up execution batches to cover the most critical scenarios.
This way, you not only integrate tighter along the risk-based delivery pipeline — which is practically almost every commercial pipeline out there today anyway — but also spend time debugging only meaningful failures. In addition, you utilize your computational force in the most eco-friendly way!
More to read
- JIRA API2, XRay API((XRay API, https://docs.getxray.app/display/XRAY/REST+API)), TestRail API3, HP ALM QC API4
- JUnit5 launcher5 and tags6 NUnit TSL7, SpecFlow Filter, Cucumber tags and run options8
Test data management
To properly execute test, you have to feed it with prepared data and configuration.
Static data is relatively easy to prepare. For example, virtualized instances of a system, each supplied with an in-memory database and predefined data sets, are pretty good for component and integration testing.
But when it comes to system or end-to-end testing, things get complicated. Certain types of tests may require dynamic control over data or changing the state of a running system.
Resource distribution and mutability problem
In Fintech, we have multiple types of test entities which have to be, on one hand, thread-safe and lockable, and on the other hand, controllable by tests. Examples include account portfolios, trading instrument configurations, or schedules.
Safety. Using the same critical entity in two parallel test threads usually results in unexpected behavior and cascade failures.To control test flow, you should avoid two parallel tests using the same entity.
Control. For many trading activities, the system has to change its state or the state of an entity. The simplest example is trading order activation when a specific market quote should pass through.
Solution
Utilize the architectural pattern which we call Test Service pattern. It is a backend component that:
- interacts directly with system entities;
- handles resource locking and distribution;
- provides simple REST API for top layer testing frameworks.
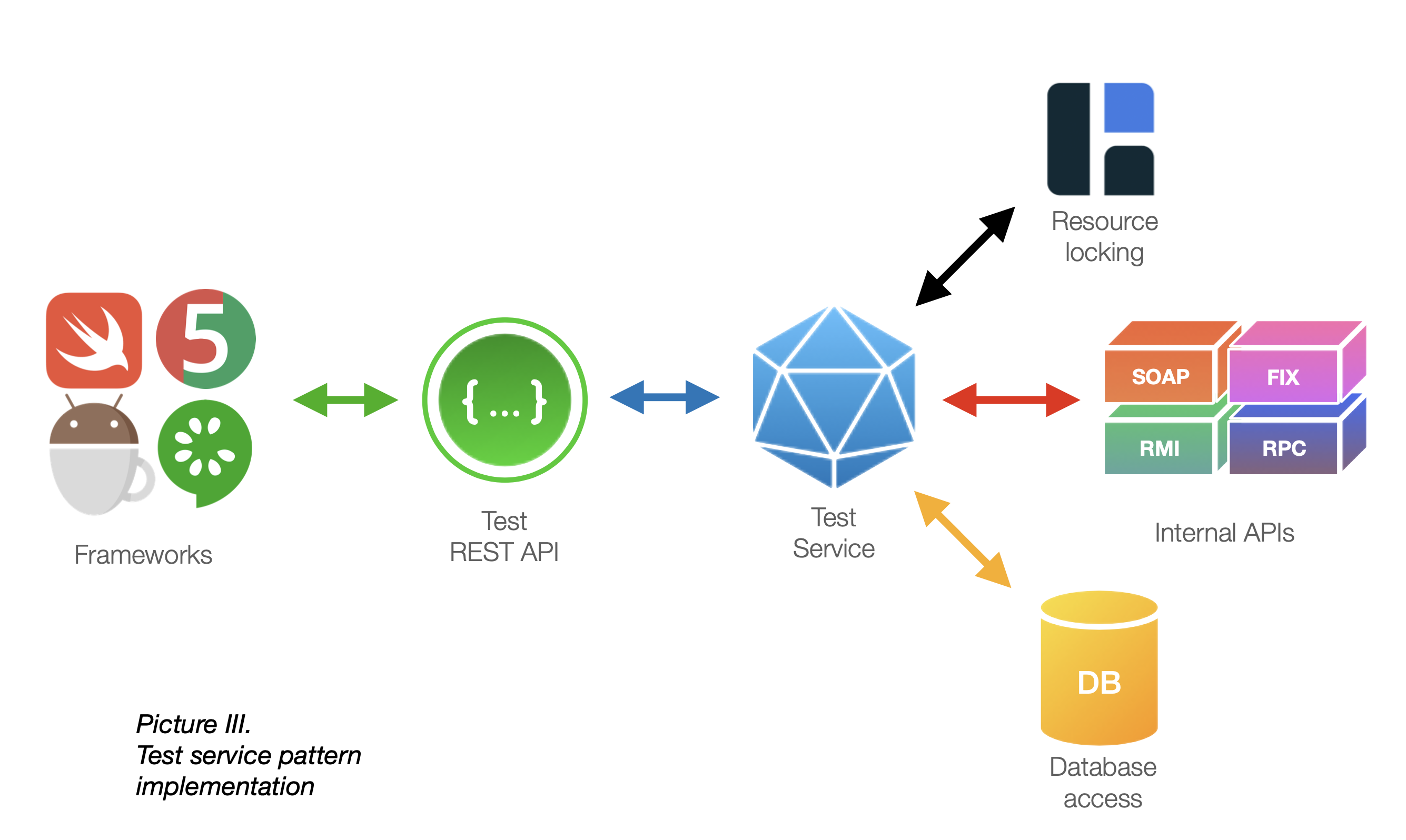
Test service is built using system APIs and usually is an integral part of system delivery. This approach eases maintenance between system versions.
Test service also handles distributed cache for resource locking using technologies like Hazelcast. Every testing framework running against a system explicitly registers its resource usage, so system entities are distributed evenly and safely.
Test Service REST API enables top-level frameworks to perform significantly complex test scenarios and standardizes system interaction among all software stacks.
The main downside is that Test Service becomes a rather powerful backdoor. It’s critical to handle it with extra care and not expose it to production.
More to read
Configuration
Another challenge that can appear on our multi-platform, multi-targeted testing journey is the pipelines maintenance problem. To illustrate it, let’s go through an example.
Tests are usually split into independent classes called functional areas. Every functional area of a product requires its own unique set of preconditions and can be tested relatively independently from other areas. During automated execution, tests from the same functional area are usually batched together first and then split into smaller subsets if needed.
Pipelines maintenance problem
For trading systems, examples of functional areas include authentication, trading activities, reporting, or third-party integrations (such as liquidity providers, payment systems or other institutional partners). In the most advanced modern systems, the number of FAs can go up to 30.
If we multiply this by the average number of 20 patches per release and apply riskbased strategy, we get 20 × 30 = 600 unique execution configurations per release.
It’s virtually impossible to manually maintain any pipeline configuration that supports this type of process.
Solution
This problem can be solved by even tighter integration of existing solutions and automation of operational routines.
It’s a good idea to start with automating our build scheduling. Check what your CI server provides as API. Chances are you can use it to manage your executions.
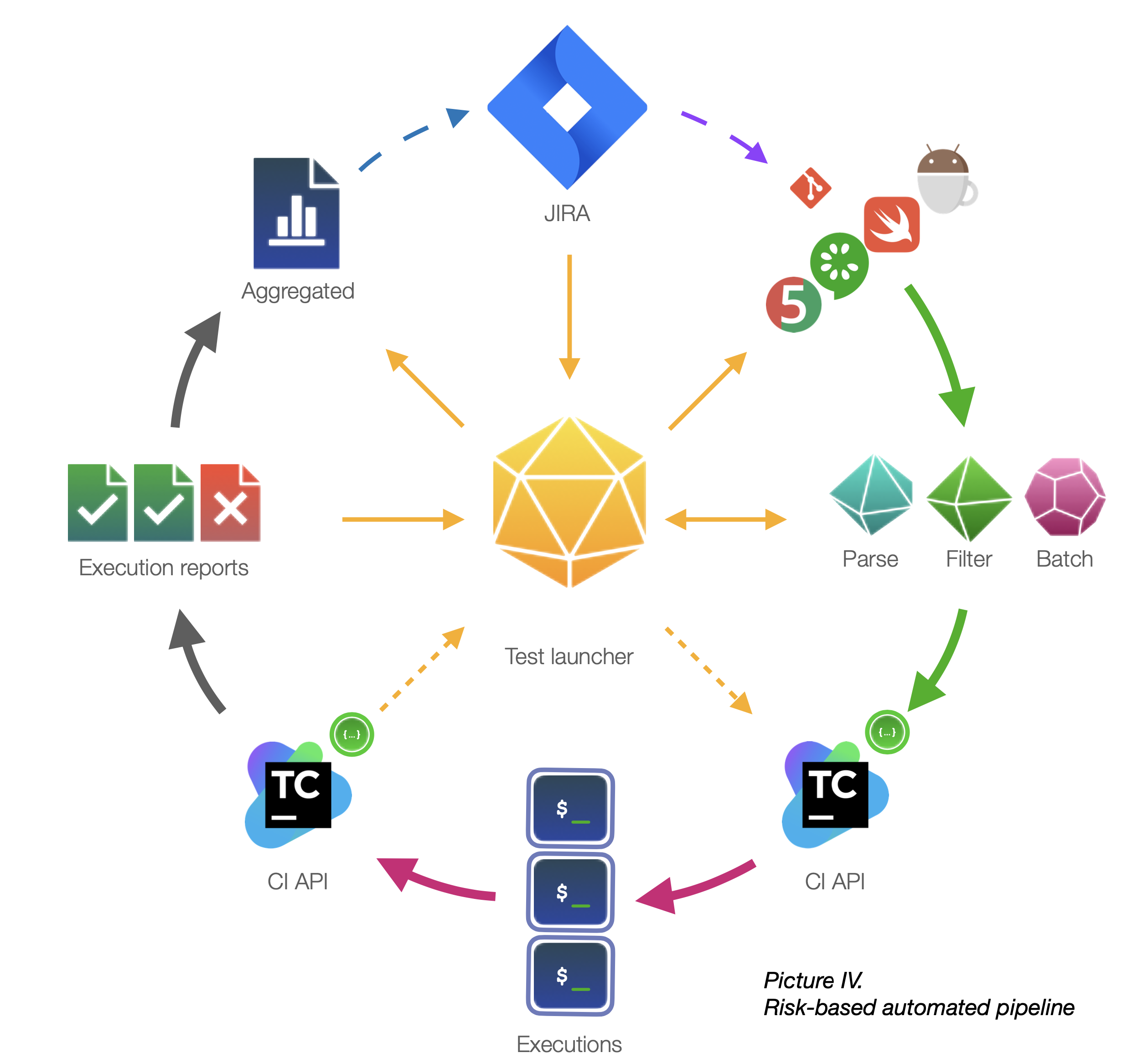
In our case, we’ve created a custom TeamCity API scheduler allowing us to split, parameterize and execute custom execution tasks in a fully automatic way.
If builds are orchestrated automatically, so shall the execution results. There are a few challenges to solve along the way:
- Parallel builds can have somewhat unpredictable execution times. To collect results properly, one needs to determine when all executions finally stop. It may be required to design some listener to monitor the status of the generated executions.
- Well-thought logic is required at the result aggregation stage. If any of the test scenarios are split into multiple threads, check if the aggregated result reflects the system state.
Our solution: after splitting and generating, a test launcher marks all generated builds with a unique tag. The launcher registers this tag in a standalone watcher. The watcher uses TeamCity API to poll and aggregate the status of all executions registered per tag. Once all executions under a certain tag have been completed, the watcher triggers result collection. Collector gets all artifacts for a given tag, then applies hierarchical logic to compose the aggregated test report.
As a result, the overall execution algorithm is practically one-button-runs-all, while under the hood it can include up to 200+ generated parallel TeamCity builds.
More to read
Conclusion
With the industry shifting more and more left and software markets becoming more and more demanding, risk-based testing has already become the most commonly used test planning technique for many Agile teams.
While getting the great benefits this method brings, it’s important to find elegant solutions for challenges arising along the way.
Join us to start finding ones together.
References
- Investopedia, Time in Force, https://www.investopedia.com/terms/t/timeinforce.asp [↩]
- JIRA API, https://developer.atlassian.com/cloud/jira/platform/rest/v3/api-group-jql/#api-rest-api-3-jql-autocompletedata-get [↩]
- TestRail API, http://docs.gurock.com/testrail-api2/start [↩]
- HP ALM QC API, https://admhelp.microfocus.com/alm/api_refs/REST/Content/REST_API/Overview.htm [↩]
- JUnit5 launcher, https://junit.org/junit5/docs/current/user-guide/#running-tests-console-launcher [↩]
- JUnit5 tags, https://junit.org/junit5/docs/current/user-guide/#running-tests-tag-expressions [↩]
- NUnit TSL, https://docs.nunit.org/articles/nunit/running-tests/Test-Selection-Language.html [↩]
- Cucumber run options, https://cucumber.io/docs/cucumber/api/#options [↩]
- Hazelcast documentation, https://circleci.com/docs/api/v2/ [↩]
- Distributed locks with Redis, https://redis.io/topics/distlock [↩]
- Building REST services with Spring, https://spring.io/guides/tutorials/rest/ [↩]
- Jenkins Remote API, https://www.jenkins.io/doc/book/using/remote-access-api/ [↩]
- GitLab API, https://docs.gitlab.com/ee/api/ [↩]
- CircleCI API, https://circleci.com/docs/api/v2/ [↩]
- Devexperts Switchboard, https://github.com/devexperts/switchboard [↩]