The Basics of Quality Assurance in Financial Applications

Testing trading system performance is a fairly new quality assurance practice that is rapidly developing and gradually taking shape. However, here and there, it still lacks common strategies and terminology, making it hard to seek help for testers who often face its subtle aspects.
Let’s talk theory
Here at Devexperts, we develop all kinds of software for financial institutions, depending on their needs. But, the main product remains the same — trading platforms. So how do we approach them in terms of performance testing? What is the process and the associated difficulties?
For starters, let’s clarify what performance testing is. It’s a practice that tests software applications under a particular workload. This measures its speed, response time, stability, scalability, and resource usage. Financial software usually means top-tier architecture that experiences heavy load, supports multiple integrations with third-party venues, and demands high throughput. Performance testing considers all these parameters and has practices applicable to each aspect.
Performance testing involves a series of different tests. Here’s a list of these tests:
- Load tests. We load a system to an expected extent to see its reaction.
- Stress tests. Here, we go a step further. What if we increase the load to a stressful extent? At what point will the system lose its ability to cope? This test is beneficial for understanding what will happen with the production release and if the system will successfully handle an influx of users.
- Soak/Endurance/Stability tests. As opposed to others, this test takes a long time. Here, we load a system for a prolonged time to see how it behaves.
- Capacity tests. These are the most interesting tests for businesses. They show the system’s capacity to handle a certain number of users.
- Scalability tests. They test a system’s scalability and how it goes through dynamic scaling in real-time.
- Volume tests. They help answer the question: what happens if the system has a large amount of data and users try to access them through numerous requests?
- Performance searches. These could be a lot of things. The aim is to find out as much info about the system’s behavior as possible. What is the system’s configuration? What will happen if we deliberately break something? How will the system restore itself?
This is a basic set for testing the performance of financial applications.
Time to practice
The architecture of trading systems
The systems are quite complex: there are numerous types of clients (front, middle, and back offices), all customers use different functionalities, and all apps are heterogeneous. A single system might have a whole package of products each configured individually and all systems always require integrations with numerous venues.
- Different client types (front office, middle office, back office)
- Variety of client apps (desktop, web, mobile)
- Variety of products (FX, equities, futures, options, cryptocurrencies, etc)
- Variety of modules (risk monitoring, alerts, charting, reporting, etc.)
- Integrations (liquidity providers, B2B, STP)
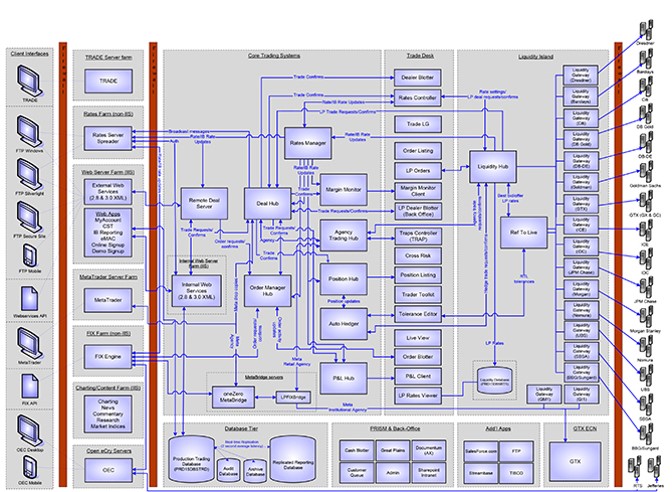
What gives more edge to trading systems is their environment with its sophisticated architecture and most of its components capable of horizontal scaling.
- Horizontally scalable front- and back-end components
- Middleware
- Databases
- Hybrid Infrastructure
So, long story short, testers of financial systems have their hands full. We are constantly involved in a variety of exciting projects. Check out our vacancies at Devexperts Career if you would like to join us — we have offices worldwide and offer remote options.
Three approaches to performance testing
There are three common approaches to testing systems. Let’s review them from the simplest to the most complex.
1. Component testing
The motto: why complicate? Let’s test each component individually. Functionality and tools are reduced to a minimum, making this testing austere — cheap and quick. This practice is attractive because it is really cheap, making it perfect for agile approaches. Component testing can help us in building tests, continuously integrating them, taking the measurements, and identifying possible issues.
Of course, it has cons. As we take a module out of a system, there is a great possibility for incorrect testing of functionality. Thus, this approach has nothing to do with real life. It is purely synthetic, giving unreliable results.
- Easy to deploy
- Simple environment
- Simple testing tools
- Fast delivey of results
- Mere simulation
- Synthetic load profiles
- Unreliable results
2. Subsystem testing
OK, we get it. Testing single components cut out of a system is not very efficient. What if we divide a system into logically related subsystems (say, an order processing module without charting) and test them?
It is relatively inexpensive because you don’t have to deploy an entire system. It’s similar to the previous practice but with a little bit more functions to test.
It’s possible to lack resources. So, maybe you’ll need a specific testing environment. From a loading issues viewpoint, this practice does not provide enough insights into how the system will behave in production. The simulation is not close enough to the real system’s use.
- Relatively easy to deploy
- Relatively simple environment
- Simple testing tools
- Fast delivey of results
- Not realistic enough load profile
- Unreliable results
3. Multichannel end-to-end testing
This one is the most interesting practice: testing everything! Multichannel end-to-end testing is the sole mentioned approach that simulates the load similar to one that a system experiences in production. This practice provides the most true-to-life results. Still, it requires systems matching to production ones as closely as possible. This practice is costly, though, due to the complex script simulation and the large data array generated that requires analysis.
- Close to real-life load profile
- Production data set
- System layout
- Realistic data flow
- Reliable results
- High environmental cost
- High system maintenance cost
- Complicated testing toolset
- Complicated results analysis
Performance testing process
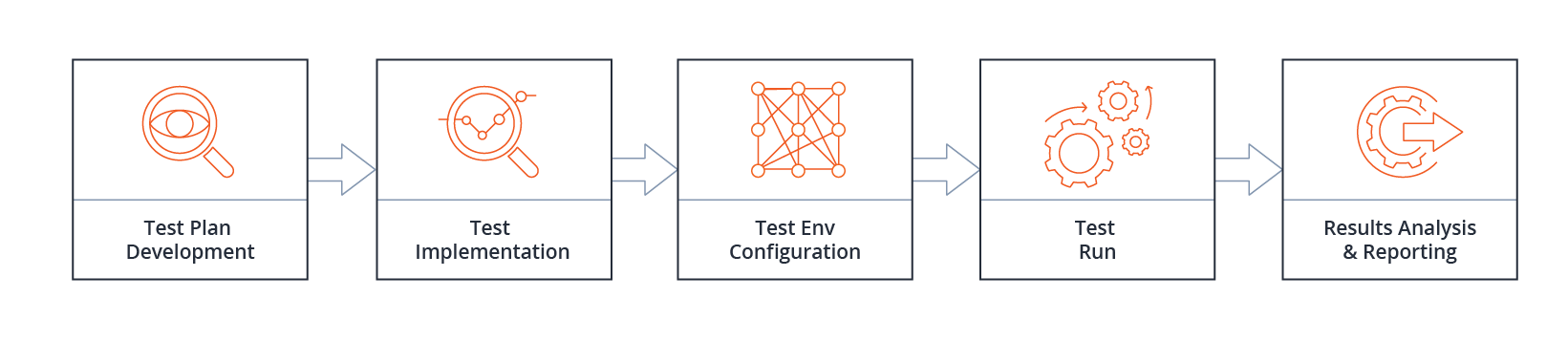
How should this process be facilitated and what stages it has. Important points.
The process is relatively easy: a customer comes to us and we start developing a test plan. After confirming the plan with the customer, we start implementing it: we configure an environment and do the testing. After this, we analyze the test results. That can be followed by any number of iterations of adjusting the test plan and additional testing.
Stress and load tests are usually rather expensive because they require a substantial workforce and resources, including testing and development engineers.
What is worth paying attention to when creating a test plan?
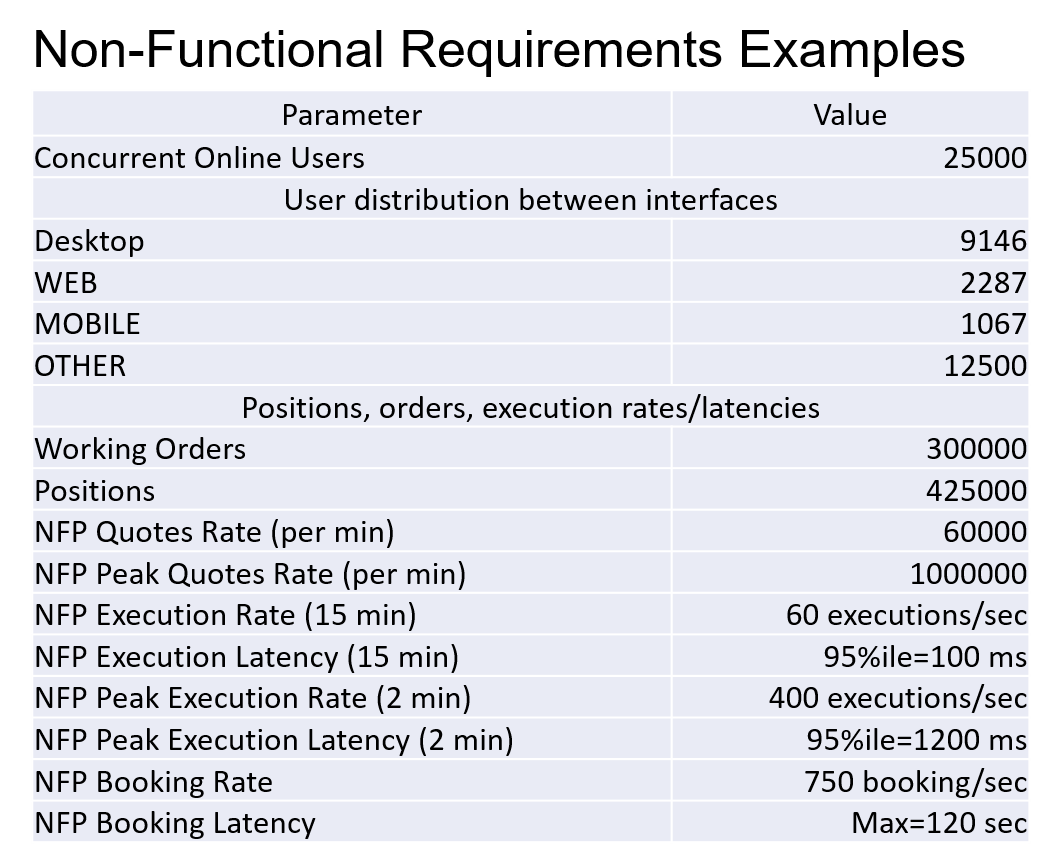
Usually, standard sections comprise a test plan representing testing intentions: what we need to test, covered features, test load profile, measured parameters, KPIs, overall system behavior, and metrics that help us understand if we’ve reached our goals.
Each test aims to provide us with an answer to a precise and narrow question. And, it is not always possible to combine part of our testing aspirations with real-life situations. That’s why it makes sense to go for quality assurance services from experienced vendors that work in the same business field as you. They have already racked their brains and know the software and industry’s ins and outs.
KPIs
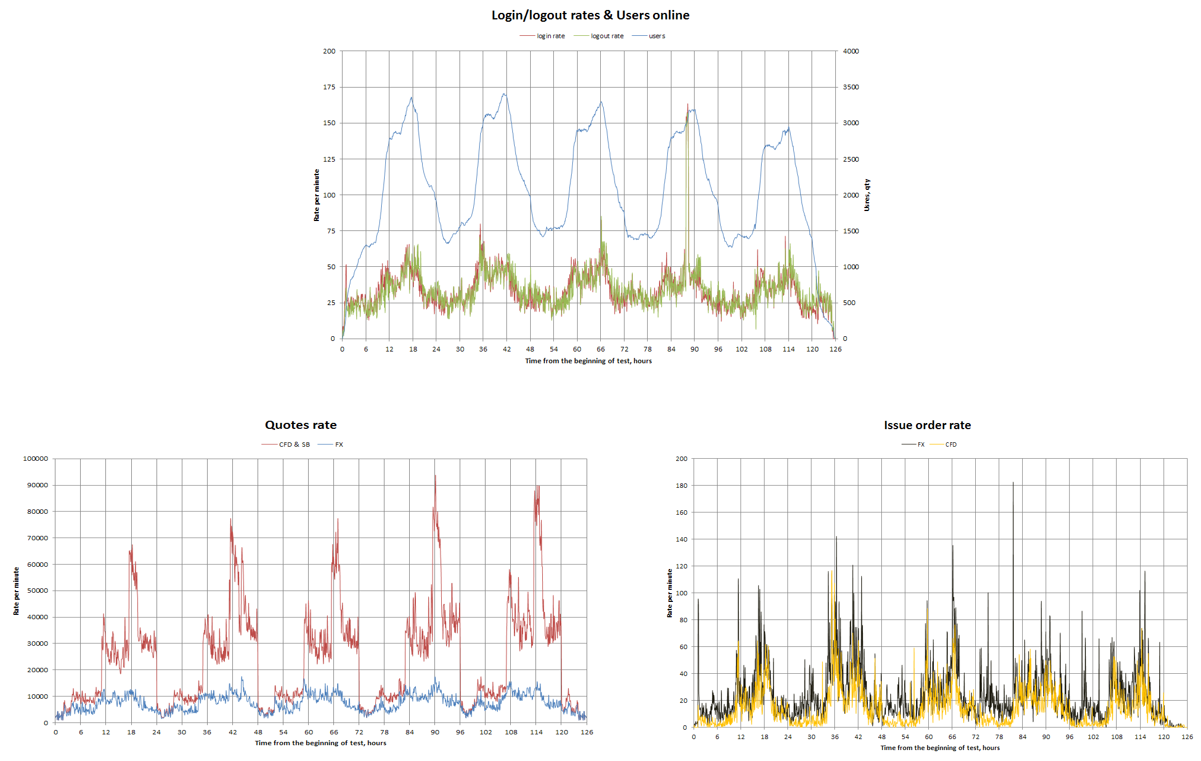
These are usually derived from the project requirements. What are the usual non-functional requirements? Most popular options: no requirements at all, “the system must be fast”, and “on average, an operation should take N microseconds”.
In the case of non-functional requirements, we should always be very careful with providing absolute numbers. It is obligatory to make the system handle the absolute majority of users’ operations within a defined time. The system must also respond at a certain speed. However, it is critical to understand the number of users, how they are distributed across the interface, and other test parameters because it drastically impacts the test results.
Load profiles
The perfect case would be to get load profiles from the current system version. But, that’s not possible when the system is still in development, so what’s left is to look up an SLA and look back at the past experience with similar systems or synthetic options—there’s no silver bullet here. It is always important to talk through all goals in detail with your customer so you don’t miss anything like operation interdependence, that can strongly impact testing results.
Test implementation
There are many performance testing products. If we dive deep into each one, we’ll find out that they are mostly concentrated on testing web environments and their functionality is not very different from each other. Some offer graphic interfaces while others don’t. They all differ in price from zero to eternity. There are cloud services and turnkey solutions. Some sell licenses and cloud hosting separately. So, it’s really hard to judge them altogether. Each testing team chooses the tool that fits them the most.
We chose to develop our own framework both to generate load and analyze the results. Although we have an in-house solution, we sometimes use JMeter or Gatling to test some web applications.
Analysis of test results
Before analyzing, you need to collect the results. The parameter that interests us is the consumption of resources. There is no unified standard; each case needs its own tuning. This stage is very important because metrics must be collected according to clauses that had been discussed when the test plan was created.
Besides this, there are also time parameters. How much time does the operation take to be performed at the user’s end? How much time does it take at each stage?
To elude any confusion with metrics, it is worth asking developers to factor them in at the very beginning of the project.
What can be analyzed?
- Current system behavior
- Comparison with previous versions
- Long-term trend analysis
- Comparison to production systems
It’s also important to compare metrics when plotting a chart: how resource consumption depends on the load, what happens to the network at certain times, etc.—there are numerous combinations, so you need to know precisely what is important in your case.
Some bits to conclude
Paying special attention to the testing environment is crucial too. Sometimes it could be a bad idea to place load generators in a corporate network if your testing system is not part of it. It could lead not only to difficulties for the current operations of your company’s employees because an external network channel ran dry but to an entire corporate network failure.
And never forget to mask user data and integrations. Are you testing an SMS mailing service? Masking will help you avoid awkward situations like sending an SMS to real clients about a spontaneous margin call on a weekend. On the bright side, this situation will test your customer service that will get many calls from your perplexed clients (wink-wink).
You can get in-depth information about our expertise and projects at Explore Full-Spectrum QA and Testing Services.