Fintech QA: In-sprint Testing

If we consider the shift-left paradigm, one reason testing should begin early is that it allows teams to prevent issues rather than fix them. Following this logic, static testing becomes as important as dynamic testing. However, this approach can also be applied to dynamic testing and it is usually referred to as in-sprint testing.
There are, most commonly, several ways to dynamically make sure software issues are logged and tracked. The most obvious one is confirmation testing: when a new version of the software is released, QA engineers check that fixes or new features have been implemented per requirements and work at least as requested. Regression testing is equally important as it can assure involved parties that the system works as intended as a whole, that new features and fixes have not affected the old scope. This list of testing types would be incomplete, however, without in-sprint testing.
In this article, we will consider how it can be beneficial to a software development cycle, what the pros and cons of such testing are and what requirements should be met in order for it to be successful. To discuss points of argument, we will use fintech software, specifically FX trading platforms, which is tested with the use of Black-Box testing techniques.
Definition and Application
From a technical standpoint, there are a few ways to implement in-sprint testing but the goal always remains the same: it exists to allow testers better integration with the development process and reporting of issues until they make it to a delivery. Consider a simple scenario where an issue lies in business logic, not the code. A client has requested to introduce a reporting mechanism that generates a CSV file that stores data requested by a regulator. This file includes data on trades performed by users from multiple accounts with different asset types where, among other things, user login and account code are stored. The problem is that requirements have these two notions (login/account) confused and switched places.
If the issue with the requirements was missed during static testing, the only way to resolve the problem described above without in-sprint testing is to assemble a build with the corrupted Pull Request (PR), push it to a testing environment and create a Defect Report (DR). The problem lies not only in the amount of formalities (like introduction of a development ticket, its processing and estimation, creation of additional branches and so on) but also in the fact that changes are usually delivered in bulk. If the mistake above is quite straightforward and can be easily isolated, then what about multiple changes gathered in a single package that affect adjoining areas? This immediately makes debugging a lot harder.
Instead, in-sprint testing allows testers to dissect any given change with surgical precision and experiment with a system that only includes one addition at a time. Then, if no problems are found, a clear and transparent delivery is approved.
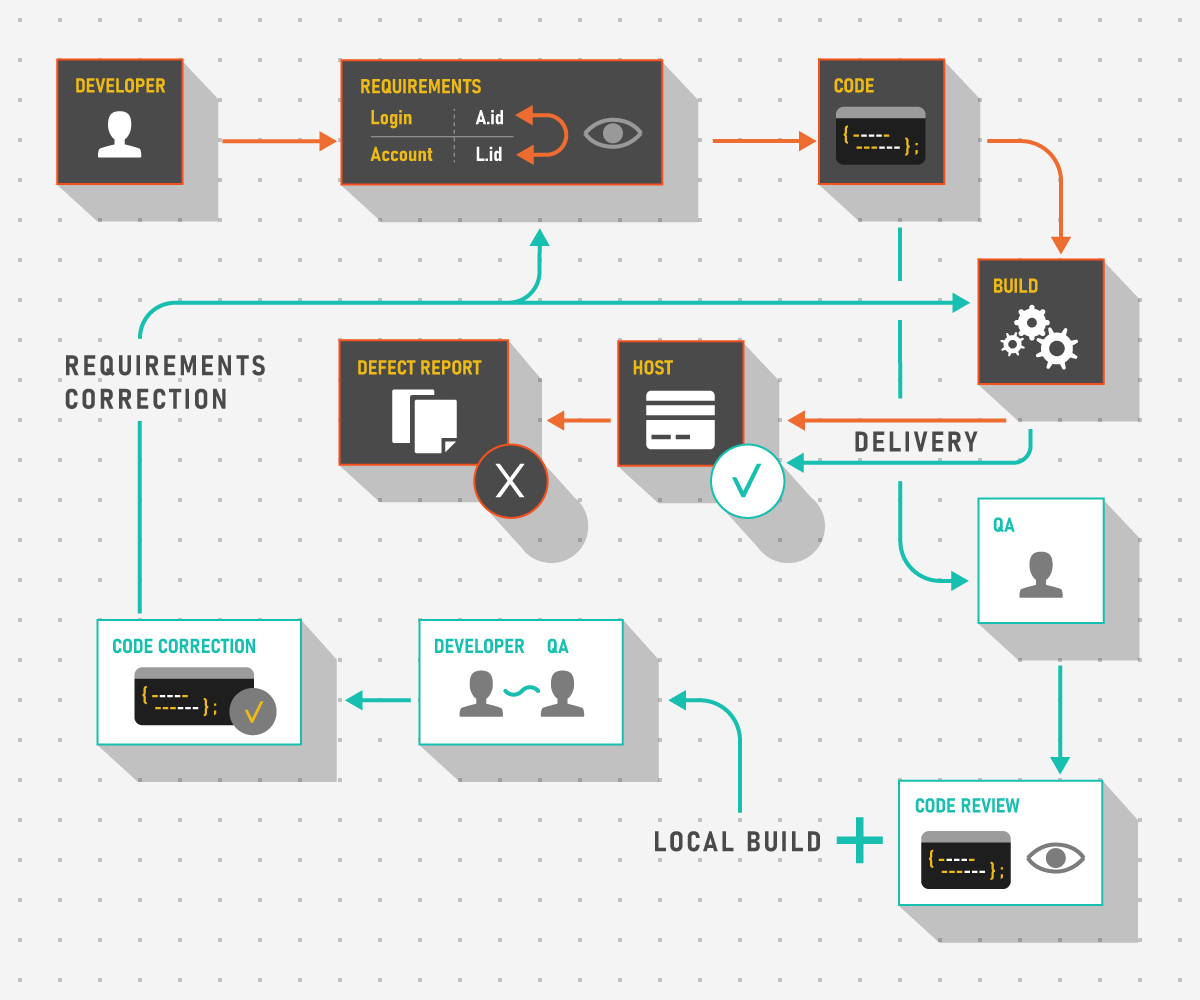
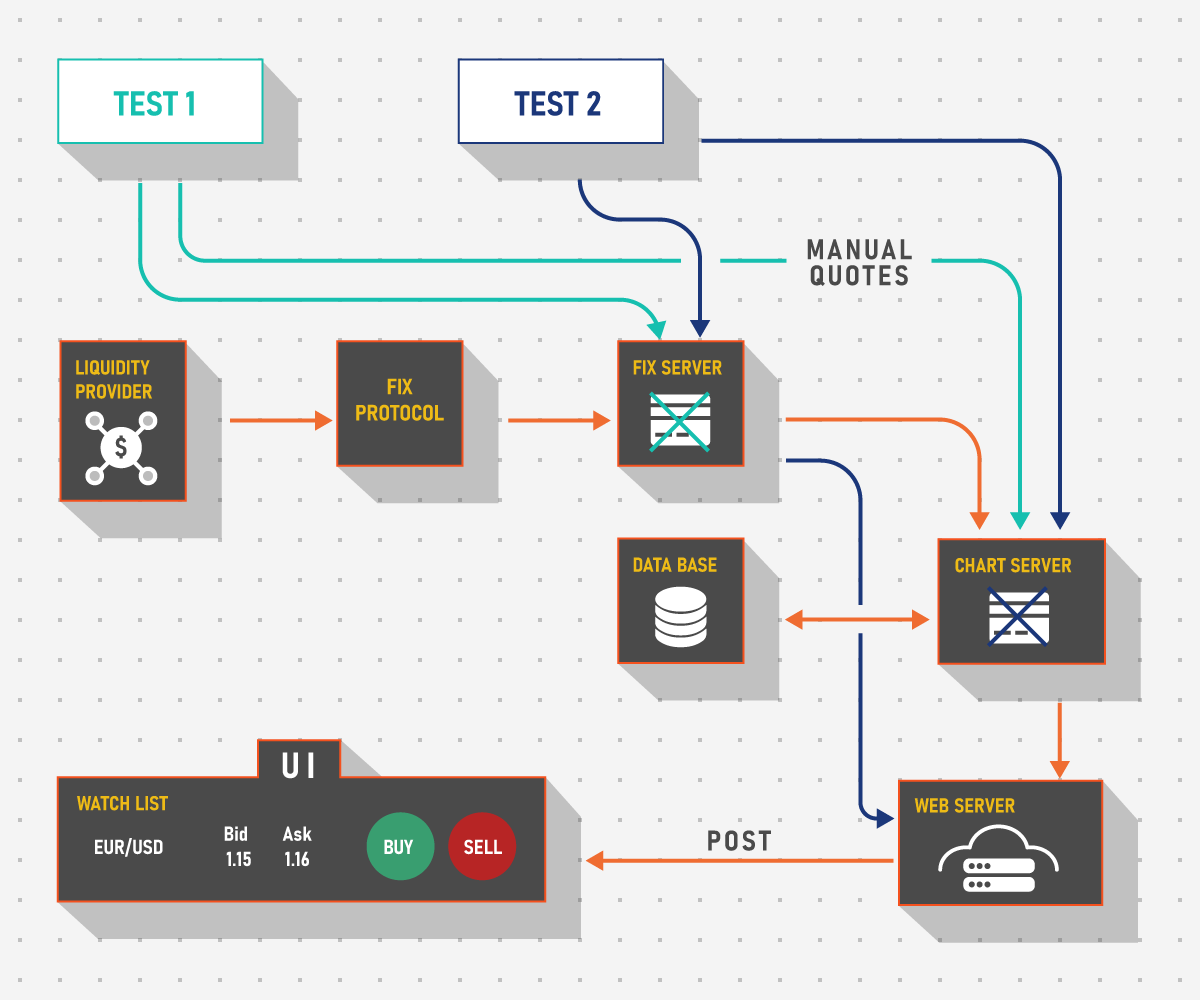
Of course, in-sprint testing can be used with harder cases as well and it can work rather well. For example, we can run several services in parallel via containerization and only use those that are required for the check, thus controlling the problematic area. For example, imagine that the UI has a Watch List widget that displays assets with current quotes at which traders can sell or buy. For some reason, when the UI is launched locally there are no quotes. By turning different co-dependent services on and off, we can profile the risk area and say that the fault lies, for instance, with our external integration where we receive data via FIX protocol from a liquidity provider, or, alternatively, with the chart server that has an issue and cannot send quotes from the Database (DB) to the UI via web server, or with any other component.
There are many cases where we can effectively use in-sprint testing to better suit testing purposes. However, there are also limitations and preconditions that must be met so that it is smooth sailing for both developers and testers.
Bottomline: In-sprint testing allows engineers to shift-left dynamic testing and get involved in PR review. The main benefit is that problems are detected in an isolated environment one by one and can be resolved with little bureaucracy.
Transparency Equals Effectiveness
Before talking about potential downsides and complications it would be good to outline conditions that are required for successful in-sprint testing. There are two main points to consider: technical suitability and formal transparency.
| Technical Suitability | Formal Transparency |
| QA engineers are excluded from reviewers for purely technical changes (Black-Box) | Any given Change Request (CR) has a description that summarizes the breakdown |
| UI elements are tested in-system, not in a sandbox, especially if they are dependent on other elements | PRs have clearly defined acceptance criteria so that the intermediary process of additional investigation is eliminated |
| PRs that depend on other PRs are tested in-system so as not to block development | Communication is maintained between developers and testers |
1. Technical Suitability
Generally speaking, not every PR is a good candidate for manual Black-Box in-sprint testing. The majority of issues can be tested physically but results may not be apparent until the system is evaluated in an assembled state. This group is composed primarily of technical changes that are hard to notice locally. If there is no clear understanding of how any given code change affects the end user, in-sprint testing is downgraded to code review which should be covered ideally by peers of the responsible developer. Keep in mind that this idea does not reinforce the notion that testers should not check code but even for White-Box testing if a change is considered refactoring without any transparent effect on the system, perhaps it is best to leave it to regression testing instead.
Another good example of technical suitability lies with the changes that can only be checked in developer tools like Storybook or similar. While it is nice to investigate an element in a sandbox for measurements, color coding and general feel, it doesn’t allow testers to know how the element will react with other components of the UI that may be developed in parallel and not be available in the tool. Combine this with the absence of formal transparency (see more on this below) and you have a PR that will take more time to check than to confirm in a build with some other changes.
Finally, if a team has a number of competencies, the work of one developer may not be available for checking until another developer provides a dependency. For one example, if there is a team that connects Frontend (FE) data with Backend (BE) via web server, their changes may not be testable until a UI feature is implemented. Consider any button in the UI that triggers data transfer to BE. If the data transfer API is ready but the button itself is not, the only way to test this is to manually send a request to BE via tools like Postman. While this may sound like a good idea, it does not cross out a necessity for system testing and it is especially obvious when the competencies are reversed.
2. Formal Transparency
Apart from technical suitability, it is always a good practice for testing to remind everyone involved that transparency of development items is key to better communication. If QA engineers are busy with other activities, they may not be always available for feature breakdown that happens between developers. Let’s not confuse grooming sessions where team members discuss requirements with feature breakdowns between developers which allow development team-leads and managers to determine how work is split between engineers. This means that any given PR may have only a part of code that will depend on other PR which is not yet opened. Without a transparent description, this leaves testers guessing if the problem they find or misalignments with design docs they spot are actual defects or just places left unfinished for the time being. Consequently, this makes testers disrupt the work of developers with additional meetings and questions that could’ve been easily avoided with clearer descriptions.
The simple truth is that communication is key and that developers should be responsible for their documentation, that is PR description and code comments as primary artifacts, just as much as a business analyst is responsible for formal requirements and a tester — for well-written test cases. If this condition is not met, the process of in-sprint testing ends up as a non-ending meeting between different stakeholders to investigate what exactly must be tested and how. Instead, if acceptance criteria are introduced by developers in the Change Requests they are working on, it makes a PR so much easier to check because the intermediary process of additional investigation is eliminated.
Bottomline: Any team prior to implementing in-sprint testing must agree on what PRs should not be tested in that way as sometimes it is more efficient to leave certain changes to confirmation or regression testing. To eliminate ambiguity, development items should have clear descriptions and transparent acceptance criteria.
Downside
As made apparent in the previous section, not everything can or should be tested in-sprint. So what should be done with leftovers? More importantly, is it enough to have only in-sprint testing?
While this type of testing is considered universal in its effectiveness, it is not a supplement for other testing activities. The application may appear operational in chunks but could break down when system-tested. To prevent this, either confirmation testing should be introduced if the deadlines are tight or better yet a full regression before any major release.
Let’s return to the example from the first section about a reporting service. Even if there are automation specialists available, it is time-consuming to prepare a test that can populate the report with all combinations of trades, asset types, account types, and permission groups. Add here different trading settings available in dealing terminals like EOD time and configurations for automatic trading strategies and you have thousands upon thousands of testing scenarios to cover. To avoid this, in-sprint testing is performed on a preliminary set of data that can be covered by a manual QA engineer who can generate a necessary amount of trades by hand, trigger a report, and check the results against the requirements.
However, this approach relies on a dangerous assumption that a live system will not have edge cases in reporting data and that all trades will never fall out of equivalence classes designated during in-sprint testing. A possible result is a working reporting service in-sprint and a failing service in a live environment.
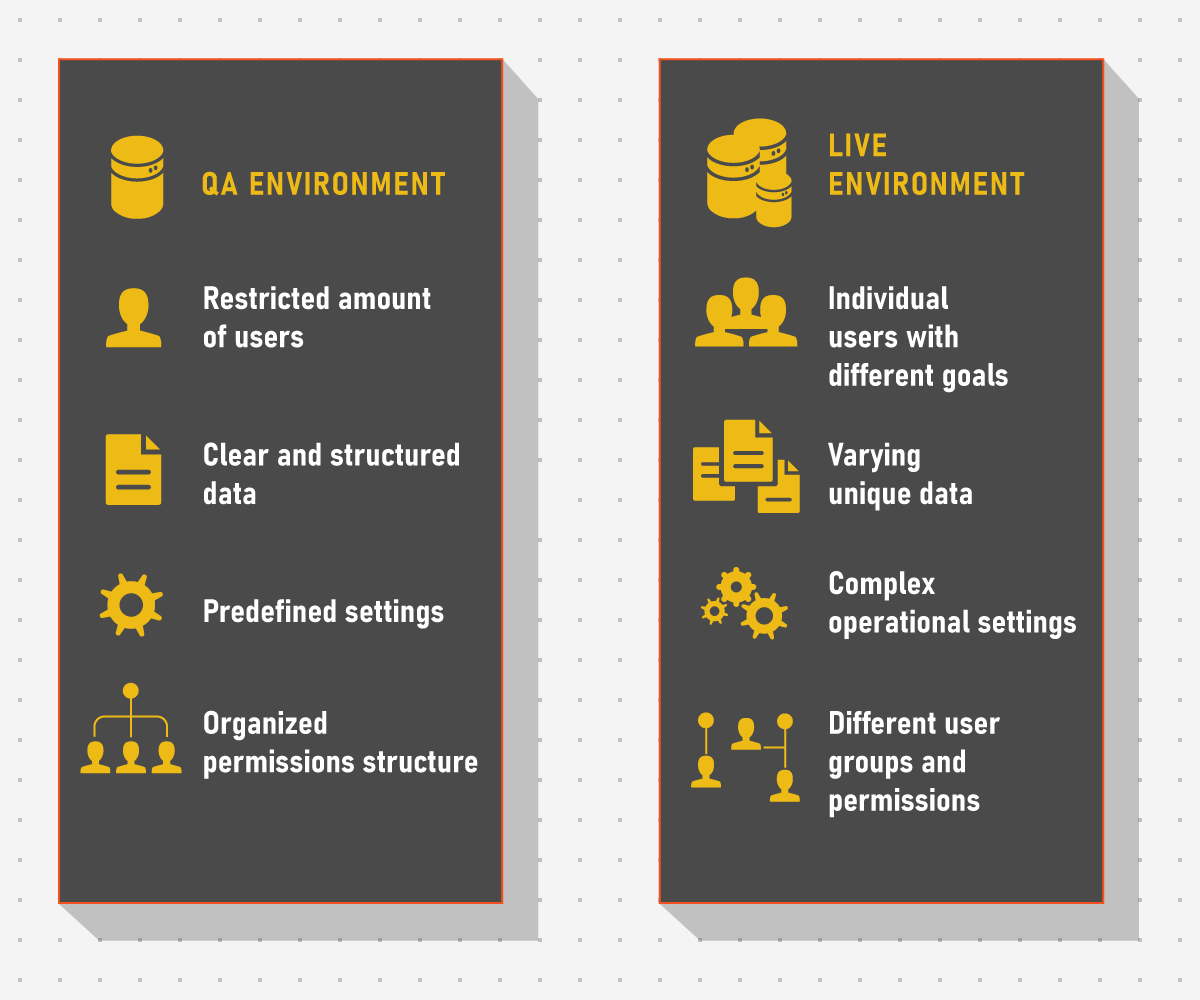
The solution to the problem is pretty straightforward, however. While in-sprint testing is optimal for “on-the-spot” checks, it can never supplement full-scale regression testing where operations are checked systematically on large sets of data or at least confirmation testing where individual bits are checked in-system and not in isolation.
Bottomline: In-sprint testing is an approach that allows proactive testing of system components, however, it never truly shows the full picture. It is not difficult to counteract negative sides with thought-out regression test sets and confirmation testing of new releases.
Summing Up
In-sprint testing as an approach shines when the team is in communication, has clear and well-defined development items that can be tested locally without too much effort. If these entry criteria are met, the result includes better requirements, better code, better understanding of business uses and obviously better software.
On the contrary, when in-sprint testing is used as a supplement for other testing activities there is a high chance the majority of problems might be missed because what works in an isolated environment can fail easily on a larger operation scale with a lot of data, users, and conditions.