Fintech QA: Preparing Good Test Cases
The definition of a good test case is elusive as it is difficult to determine the criteria for evaluation. Thus, we will not be discussing specific aspects on how to write test cases, or what approaches to use for better efficiency, as this is more of an ISTQB syllabus topic.
Instead, we will focus on two facts about testing documentation:
- It is a reinforcement of the client’s thinking.
- It can be a bottleneck for corner-type issues.
When creating test cases, engineers analyze the requirements from the user’s standpoint, imagining and emulating the described conditions. Doing so is in itself a basis for better testing and higher client satisfaction. However, this approach should be handled with care as not only does it lead to better testing artifacts, but also opens a way for unstructured testing.
In the scope of this article, we will look at testing solutions applicable to the financial sector, specifically FX trading platforms, and how the final product can benefit from looking through the testing lens. If you are fascinated with fintech and especially brokerage trading software, head to our website for career opportunities.
Expanding the requirements
The quality of a product is its implementational closeness to the documented vision referred to as requirements. What then makes quality an ever eluding concept is changeability of requirements, their adaptation to shifting needs or arising challenges.
This implies that when testing an application step by step so that it is relevant to the finalized requirements, it is a good practice to keep an eye out for improvement opportunities. Good test cases reveal the project’s weak sides.
Consider the following part of requirements for automatic order processing system:
Execute orders with the worst price available, taken from a period (client requested price timestamp + delay time). In case there is at least 1 client price received within delay that fits the Slippage distance, an order shall be filled with the worst price that fits the Slippage corridor or be rejected.
The basic implementation of this requirement stood on the FX broker’s (our client) assumption that the fluctuation of prices can come to their benefit. Usually, FX brokers make money by either taking a commission or acting as a counterparty to their clients’ trades. In our example, the broker acts as the counterparty and is interested in winning against the trader.
Let’s say that an end user has requested a Buy order to be executed when the market reaches the price of 0.85 with Slippage (maximal available deviation from the requested price) set to 0.02. While the user witnesses the price go down from 1.0 to 0.81, the system registers the following price levels: [0.87, 0.84, 0.83, 0.81], where the lowest acceptable price in the Slippage corridor is 0.83, and 0.81 leads to rejection of the order. In this particular example, Slippage allows the broker to limit the risks and not fill the order that is too unprofitable for them (price @ 0.81) while still allowing the user to make extra profits (Buy price @ 0.83 instead of @ 0.85). Note that user-positive Slippage is not common.
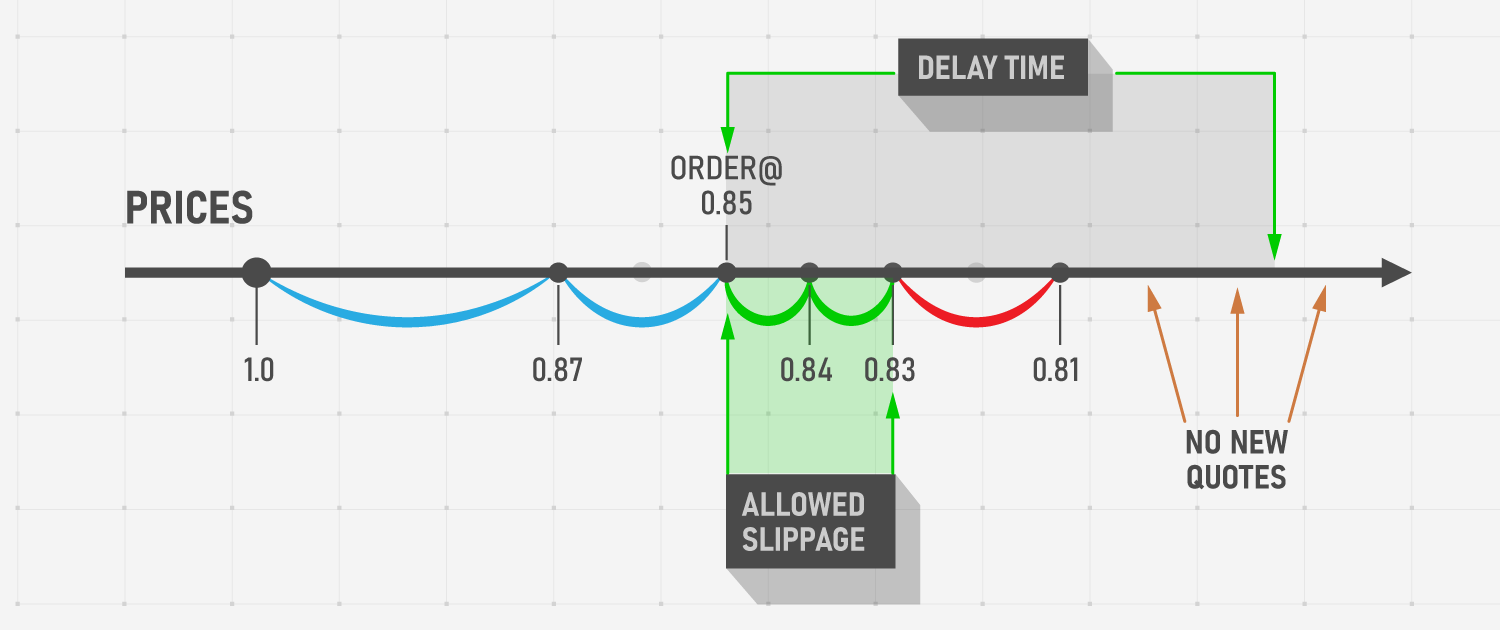
Imagine that you have to create test cases for this requirement. You apply equivalence partitioning and define which sets of data will fail the test and which will lead it to succeed by defining boundary values. Applying the data leads to test results that beg the question, “If the system already knows how to store incoming quotes during the delay, why don’t we take the latest applicable quote and disregard the quote that would lead to rejection?”
Not only does this solution decrease the amount of rejected orders, it also gives the client that owns the software more benefits. Following this logic, if during the delay period a quote was received that would otherwise lead to a rejection of an order, the worst saved quote would be applied instead. The final piece of requirements would then look like this:
Execute orders with the worst price available, taken from a period (client requested price timestamp + delay time) In case if there is at least 1 client price received within delay that fits the Slippage distance AND another price that exceeds it, an order shall be filled with the worst price that fits the Slippage corridor.
This application of testing allows the requirement expansion because documentation is not taken for granted. Instead, it is iterated on with the help of correctly applied testing techniques and thinking. It is always easier to just look at the requirements and leave it for someone else to refine and shape, to do testing word for word without applying logical concepts that may benefit the end users, but the reverse of that is higher customer satisfaction and more shaped-out user experience.
Bottomline: Use the possibility of creating test cases as a way to further research the requirements. Do not take someone else’s take on the vision of the product for granted. Tests are there to help you systemize the use cases and reveal a bigger picture, not to check the requirements word for word.
Expanding the test grid
The above section comes to show that not every test case can and should be exported directly from the requirements. Sometimes, there are blind zones in the implementation that simply fall out of what can be effectively described in words or shown in the design documents. Some pieces of functionality that fit general logic of trading do not require in-depth description. Ironically, the most obvious things are the most prone to falling apart as soon as they are implemented.
Imagine the situation where you have a new order entry screen for a FLEX option that allows you to specify
- the amount of legs (orders) for the strategy
- all the parameters associated with those legs.
The requirements state the following:
‘Leg Premium’ field defines option leg’s premium, calculated depending on the convention.
A user can add two Vanilla legs where some fields should be interconnected (e.g., if Delivery Dates of both Vanilla legs are identical, they will share the same Forward Reference price).
Somewhere in the code, a defect was introduced that subscribed premium calculation to Delivery Date check. Now when a user enters a price for the leg that has the same Delivery Date as another leg, the premium for both legs is calculated using the price of the active one. How would we approach this situation in terms of test coverage?
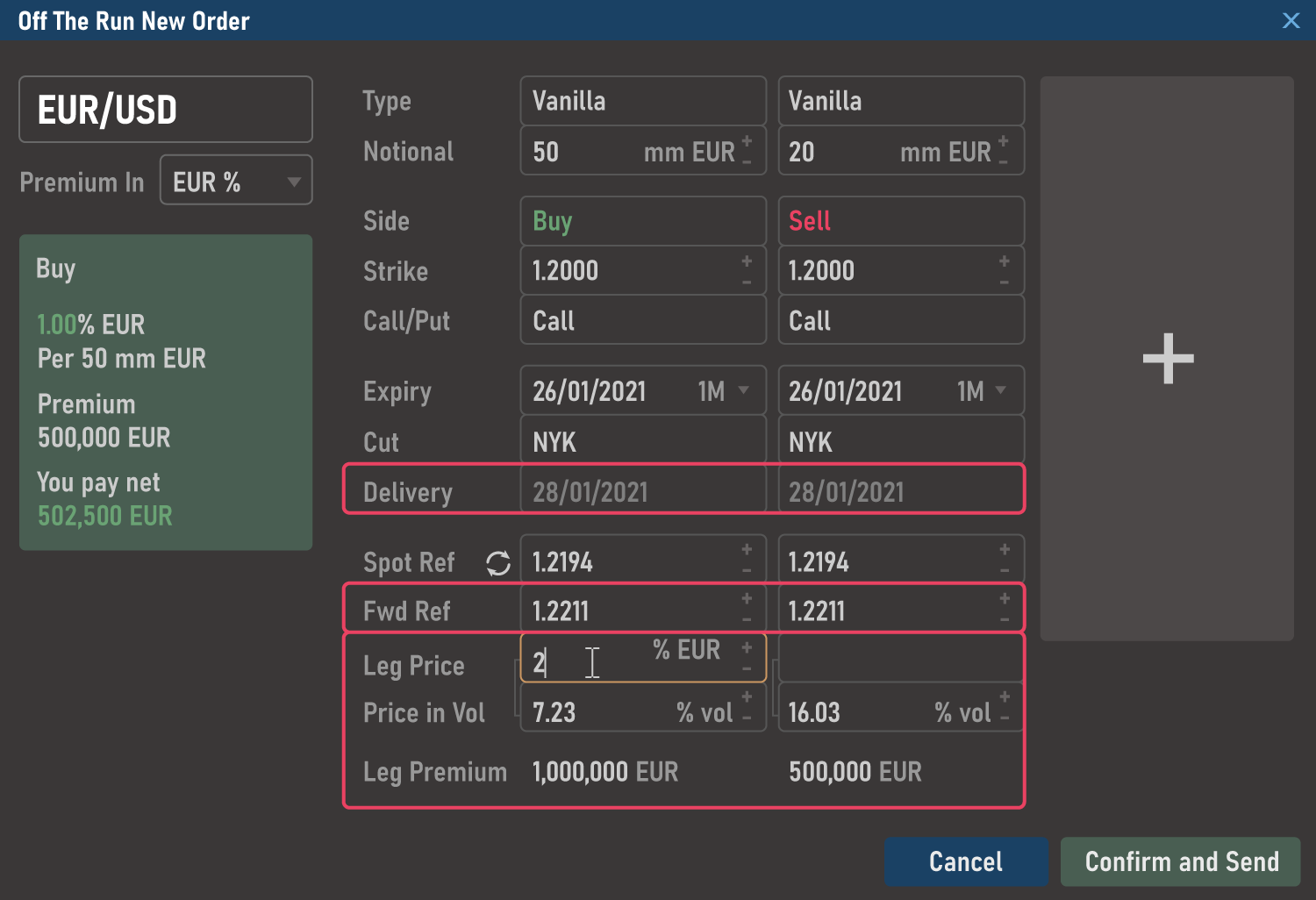
On one hand, it is not like an analyst should write down that each Vanilla leg’s premium should be independent from any other leg’s, because it is obvious from the short description provided in the requirement above.
On the other hand, if a tester follows the requirements line by line and creates test cases to check the functionality of a Vanilla leg type, there is little chance that a test case would be created just to test codependency of premiums. There would be a test for checking the price field, the premium field and their codependence on each other in the scope of one leg, but not two, as two identical types of legs do not fall under different equivalence partitions; it is implied that they are independent.
Surely, it would make sense if the requirement for codependence of delivery dates and forward rates was introduced around the same time the functionality for two legs was. However, what if such dependency was introduced much later and the case of checking premiums simply slipped off the grid by that point? The only solution to finding such a defect is to explore the application, which, in this case, thankfully was in the most visible of all places. The real question, however, remains: how would we approach the test coverage situation?
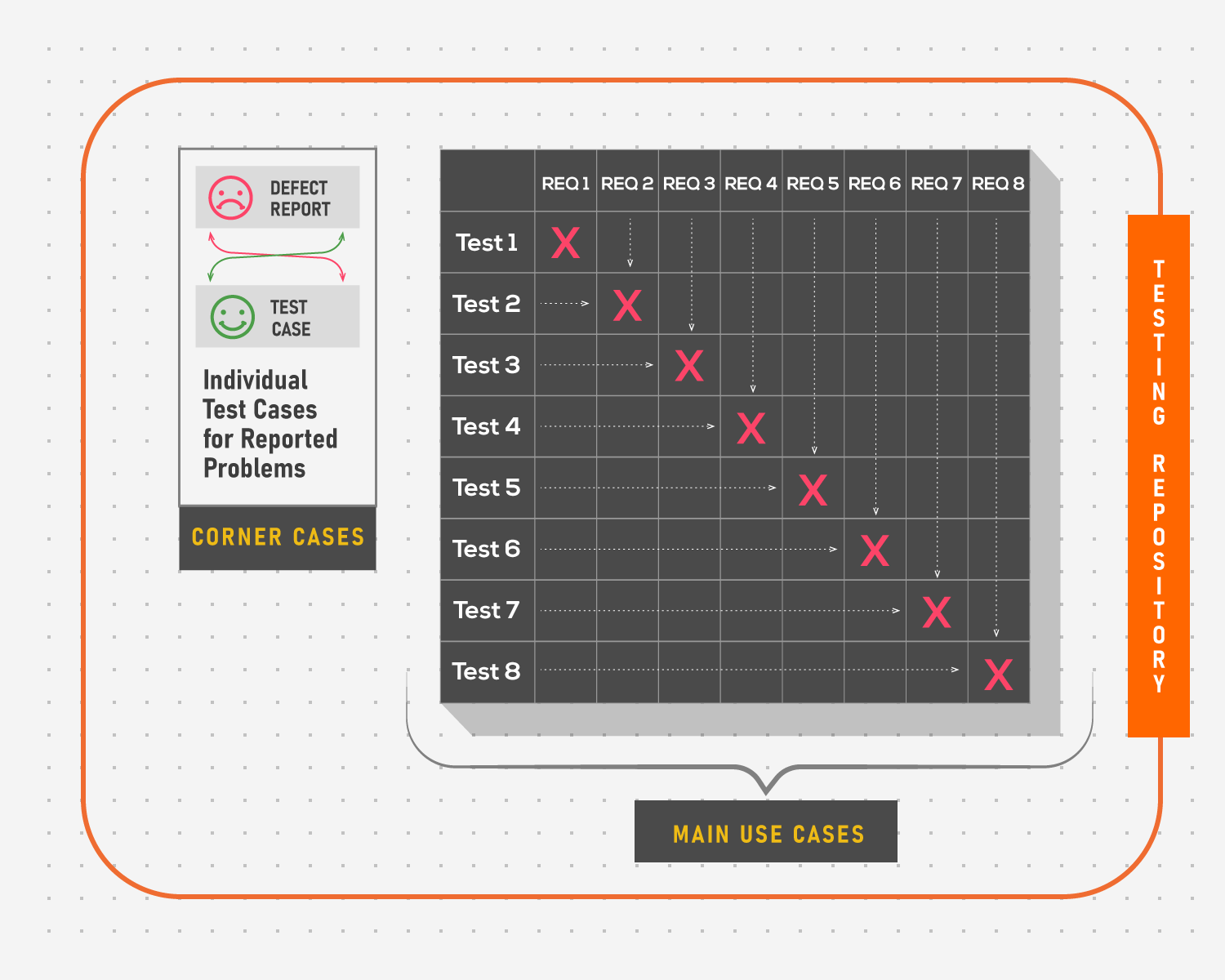
The basic idea is that every defect report should be covered by a test case that can reproduce it. In a situation where the location of a defect is outside the general testing matrix, a new, unlinked test case should be introduced to test that corner case.
The benefit of this is obvious: the chance of encountering the same problem in this or similar project will be minimal, or in the scope of risk control. Theoretically, if corner cases are included into regression runs, all problematic places that have been found earlier should now be covered. However, the solution is not ideal.
One of the principles of testing states that exhaustive testing is impossible. Following this premise, our test repository will be getting bigger and bigger over time, including more and more found issues. This, however, leads to the second, more prominent problem of controlling the havoc into which the repository will slowly but steadily descend as more unlinked tests are introduced.
There are several ways to address this issue, none of them ideal. For one, analysts can add notes to requirements stating more specific aspects of each functionality so that testers can safely link the tests. This approach requires additional effort from the analysts and floods the requirements with a potentially endless list of remarks, some of which will inevitably become obsolete.
Another way of dealing with these tests is to separate them into a folder devoted only to global regression runs and keep them as standalone additions to more frequent sanity and smoke runs. This way, however, it will be almost impossible to find specific test cases in the pile of others over time or make sure that none of the issues have resurfaced after each new update. At least, this way the main repository will remain intact.
Bottomline: Keep in mind corner cases when testing the application, link the found defects to stand-alone test cases that fall off the main testing grid. Additionally, keep track of the separate test cases to prevent repository unsystematic overload.
To summarise
The topic of “good” test cases falls under the category that always causes debate. It seems that some things attract individuality. In this regard, writing test cases is no exception as it requires an approach that works for the project and the team and there is no one way to do it. However, there are still concepts that can be applied while writing testing documentation.
First, testing is a tool, like development, to make a product that satisfies clients. A proactive approach to creating test cases should be taken where testers analyze the requirements based on the use cases documented in the tests, not the other way around where tests just reinforce the current version of requirements.
Second, no amount of detail in the requirements will ever remove corner cases from the application. The “good” approach is to keep test cases ready to document problematic places for regressions and upcoming projects. The downside though is the need to keep the ever-growing repository in check.
The key concept to understand is that testing and test documentation are not the opposite of development and coding, or product analysis and requirements. These three pillars support the successful delivery of a product to production and should complement each other, not just stick to their area of responsibility.